

机器学习 quick access
机器学习quick access
什么是机器学习
计算机程序从经验E中学习解决某一任务T,进行某一性能度量P,通过P测定在T上的表现,因经验E而提高
监督学习:包含了正确答案的数据集
classification problem
regression(回归) problem (regression 意思是设法预测连续值的属性)
无监督学习:没有label的数据集
交给机器一个数据结构,自动分析
聚类问题(eg 新闻,降噪)
模型描述
数据集
用
假设函数(Hypothesis)
称为模型参数
代价函数
我们需要尽量减少M的值,
梯度下降算法(Batch Gradient Descent)
不断更新
这里
逐步寻找局部最低点,从而得到代价函数的其中一个局部最优解(不一定是最值)
每一步下降都遍历了整个训练集的样本
线性回归的梯度下降(Gradient Descent)
凸函数只有全局最优解,没有局部最优解,只要使用线性回归算法就会找到全局最优解
当只有二维的时候:
后面的 是求偏导时的对 对 求偏导出现的
总结线性回归算法
注意:约定
特征缩放
当数据集数据差距太大时,梯度下降可能不会直接指向圆心下降,而是震荡摆动逐步逼近圆心,这个时候可能会花很久时间
这个时候使用特征缩放,例如将大数据那一个特征,整体除以2000
同时还可以对于同一个特征值整体加减乘除,使他们标准化,这样能大大提升我们梯度下降的效率
学习率选取
绘制不同学习率下的
多项式回归
具体参考泰勒展开,其中多项式也可以含有根号等,只有合理的模型,没有最好的模型
正规方程(Normal Equation)
examples: m=4
| Size | Number of bedroom | Number of floors | Age of home | Price | |
|---|---|---|---|---|---|
| x_0 | x_1 | x_2 | x_3 | x_4 | y |
| 1 | 2104 | 5 | 1 | 45 | 460 |
| 1 | 1416 | 3 | 2 | 40 | 232 |
| 1 | 1534 | 3 | 2 | 30 | 315 |
| 1 | 852 | 2 | 1 | 36 | 178 |
将数据集合成矩阵以及向量
则当X为满秩时可以得到
用此方法不需要对于特征进行缩放
比较来说,梯度下降需要选择合适的学习率
因此需要多次运行绘制曲线找到最佳学习率,而正规方程只需要计算一次,但是正规方程不适合于大维数矩阵,因为矩阵维数规模过大,无法求逆 特征个数少于一万通常用正规方程,反之梯度下降
分类
logistic回归算法
得到的是y=1时的概率
激活函数(Sigmoid function)
决策界限
画出一条线(可由泰勒展开)将所有样本分类成两部分,之后根据激活函数将假设函数的结果大于0或小于0拟合成0或1
分类问题代价函数
将cost函数合并成一个函数,不再分y的情况去讨论
So there‘s the Logistic regression cost function:
多元分类问题
通过建立多个分类器,每个分类器将其中一个元素和其他元素进行分类,得到是该元素的概率,多个分类器协同工作得到分别是每个元素的概率最后选择概率最大的输出,也是多层感知机的原理
过拟合(overfitting)问题
过度拟合:当假设函数存在太多模型参数时,我们没有很多的数据对假设函数进行约束,从而得到了不好的假设函数
1、舍弃一些特征量
2、正则化,减少特征量数量级
的数量级以弱化特征对模型的影响
正则化
因为过拟合的存在,所以我们可以使用正则化去弱化特征对模型的影响,但是我们并不知道需要去弱化哪一个或哪几个,因此选择全部弱化
正则化后代价函数
是一个较大的数,但是不能过大,否则所有参数都会接近0,变成欠拟合的结果 这里实际上没有对
进行正则化,实际上加入与否不影响
正则化后的梯度下降式
正则化后正规方程的式
神经网络
即通过多层,第一层、隐藏层、最终层,每一层都是一组假设函数将上一层的特征量提取,最后通过最终层输出得到假设
多元分类
在最后一层建立一个多元的向量层,每一个元素判断是否是其中一个元
多元分类问题代价函数
代价函数最小化算法
反向传播算法
引入
eg : 四层的神经网络
pytorch
2 预备知识
2.3.2 Tenser
Tensor是这个包的核心类,如果将其属性.requires_grad设置为True,它将开始追踪(track)在其上的所有操作(这样就可以利用链式法则进行梯度传播了)。完成计算后,可以调用.backward()来完成所有梯度计算。此Tensor的梯度将累积到.grad属性中。
Function是另外一个很重要的类。Tensor和Function互相结合就可以构建一个记录有整个计算过程的有向无环图(DAG)。每个Tensor都有一个.grad_fn属性,该属性即创建该Tensor的Function, 就是说该Tensor是不是通过某些运算得到的,若是,则grad_fn返回一个与这些运算相关的对象,否则是None。
2.3.3 梯度
因为out是一个标量,所以调用backward()时不需要指定求导变量:
out.backward() # 等价于 out.backward(torch.tensor(1.))注:torch.mean()返回是矩阵的平均值
数学上,如果有一个函数值和自变量都为向量的函数
而torch.autograd这个包就是用来计算一些雅克比矩阵的乘积的。例如,如果
那么根据链式法则我们有
grad在反向传播过程中是累加的(accumulated),这意味着每一次运行反向传播,梯度都会累加之前的梯度,所以一般在反向传播之前需把梯度清零。
xxxxxxxxxxout3 = x.sum()#清零x.grad.data.zero_()out3.backward()print(x.grad)求梯度的时候是对于前一层每一个求
所以结果存储在前一层对应项中
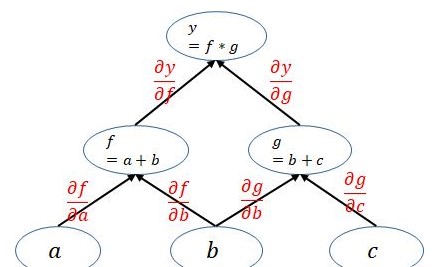
来看一些实际例子。
xxxxxxxxxxx = torch.tensor([1.0, 2.0, 3.0, 4.0], requires_grad=True)y = 2 * xz = y.view(2, 2)print(z)现在 z 不是一个标量,所以在调用backward时需要传入一个和z同形的权重向量进行加权求和得到一个标量。
xxxxxxxxxxv = torch.tensor([[1.0, 0.1], [0.01, 0.001]], dtype=torch.float)z.backward(v)print(x.grad)
再来看看中断梯度追踪的例子:
xx = torch.tensor(1.0, requires_grad=True)y1 = x ** 2 with torch.no_grad(): y2 = x ** 3y3 = y1 + y2
print(x.requires_grad)print(y1, y1.requires_grad) # Trueprint(y2, y2.requires_grad) # Falseprint(y3, y3.requires_grad) # True可以看到,上面的y2是没有grad_fn而且y2.requires_grad=False的,而y3是有grad_fn的。
此外,如果我们想要修改tensor的数值,但是又不希望被autograd记录(即不会影响反向传播),那么我么可以对tensor.data进行操作。
xxxxxxxxxxx = torch.ones(1,requires_grad=True)
print(x.data) # 还是一个tensorprint(x.data.requires_grad) # 但是已经是独立于计算图之外
y = 2 * xx.data *= 100 # 只改变了值,不会记录在计算图,所以不会影响梯度传播
y.backward()print(x) # 更改data的值也会影响tensor的值print(x.grad)
3 深度学习基础
3.1 线性回归
优化算法
当模型和损失函数形式较为简单时,上面的误差最小化问题的解可以直接用公式表达出来。这类解叫作解析解(analytical solution)。本节使用的线性回归和平方误差刚好属于这个范畴。然而,大多数深度学习模型并没有解析解,只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值。这类解叫作数值解(numerical solution)。
在求数值解的优化算法中,小批量随机梯度下降(mini-batch stochastic gradient descent)在深度学习中被广泛使用。它的算法很简单:先选取一组模型参数的初始值,如随机选取;接下来对参数进行多次迭代,使每次迭代都可能降低损失函数的值。在每次迭代中,先随机均匀采样一个由固定数目训练数据样本所组成的小批量(mini-batch)
在训练本节讨论的线性回归模型的过程中,模型的每个参数将作如下迭代:
在上式中,
线性回归的表示方法
我们已经阐述了线性回归的模型表达式、训练和预测。下面我们解释线性回归与神经网络的联系,以及线性回归的矢量计算表达式。
神经网络图

在图所示的神经网络中,输入分别为
矢量计算表达式
向量相加的一种方法是,将这两个向量按元素逐一做标量加法。向量相加的另一种方法是,将这两个向量直接做矢量加法。结果很明显,后者比前者更省时。因此,我们应该尽可能采用矢量计算,以提升计算效率。
3.2 线性回归的从零开始实现