

MPI并行程序设计
MPI
The Message Passing Interface standard
MPIQuick Access高性能计算之并行编程第一部分 并行程序设计基础第一章 并行计算机1.1并行计算机分类1.1.1指令与数据1.1.2储存方式1.2物理问题在并行机上求解第二章 并行编程模型与并行语言2.1并行编程模型2.2并行语言第三章 并行算法3.1 并行算法分类3.2并行算法的设计第二部分 基本的MPI并行程序设计第四章 MPI简介4.1 什么是MPI4.2 MPI的目的4.5 MPI的产生第五章 第一个MPI程序5.1 MPI实现的“‘Hello World”5.1.1 用FORTRAN77+MPI实现第六章 六个接口构成的MPI子集6.1子集的介绍6.1.1 MPI调用的参数说明6.1.2 MPI初始化6.1.3 MPI结束6.1.4当前进程标识6.1.5通信域包含的进程数6.1.6消息发送6.1.7消息接收6.1.8返回状态status6.2 MPI预定义数据类型6.3 MPI数据类型匹配和数据转换6.3.1 MPI类型匹配规则6.3.2 数据转换6.4 MPI消息6.4.1 MPI消息组成6.4.2 任意源和任意标识6.4.3 MPI通信域第七章 简单MPI程序示例7.1 用 MPI 实现计时功能7.2 获取机器的名字和MPI版本号7.3 是否初始化及错误退出7.4 数据接力7.5 任意进程间相互问候7.6 任意源和任意标识的使用7.7 编写安全的MPI程序第八章 MPI 并行程序的两种基本模式8.1 对等模式的MPI程序设计8.1.1 问题描述——Jacobi迭代8.1.2 用MPI程序实现Jacobi迭代8.1.3 捆绑发送接收实现Jacobi迭代8.1.4引入虚拟进程后Jacobi迭代8.2主从模式的MPI程序设计8.2.1 矩阵向量乘8.2.2主进程打印各从进程的消息第九章 不同通信模式MPI并行程序的设计9.1标准通信模式9.2缓存通信模式9.3同步通信模式9.4就绪通信模式9.5总结第十章 MPICH的安装与MPI程序的运行第十一章第十二章 非阻塞通信MPI程序设计12.1 阻塞通信12.2非阻塞通信介绍12.4非阻塞通信与其他三种通信模式的组合12.5非阻塞通信的完成12.6.1非阻塞通信的取消12.6.2非阻塞通信对象的释放12.7消息到达检查12.8非阻塞通信又须接受的语义约束12.10重复非阻塞通信第十三章 组通信MPI程序设计13.1组通信概述13.1.1 组通信的消息通信功能13.1.2 组通信的同步功能13.1.3 组通信的计算功能13.2广播13.3收集13.4散发13.5组收集13.6全互换13.7同步13.8规约13.11组规约13.13扫描第十四章 具有不连续数据发送的MPI程序设计14.2 新数据类型的定义14.2.1 连续复制的类型生成14.2.2 向量数据类型的生成14.2.3 索引数据类型的生成第十五章 MPI的进程组和通信域15.2 进程组的管理15.3 通信域的管理15.4 组间通信15.5属性信息第十六章 具有虚拟进程拓扑的MPI程序设计16.2 笛卡尔拓扑16.3 图拓扑第十七章 MPI对错误的处理
Quick Access
- What is MPI
MPI is a library specification for message-passing(这是一种并行编程模型), proposed as a standard by a broadly based committee of vendors, implementors, and users.
- 是一种库描述,不是一种语言。共有上百个函数调用接口,提供与C和Fortran语言绑定的接口。
- MPI是一种标准或者规范的代表,不是特指某一个对它的具体实现
- MPI是一种消息传递编程模型,并成为这种编程模型的代表和标准
- MPI是为了在 massively parallel machines and on workstation上都有高性能而设计
高性能计算之并行编程
第一部分 并行程序设计基础
第一章 并行计算机
1.1并行计算机分类
1.1.1指令与数据
为什么要采用并行计算
加快速度,在更短时间内解决相同问题
节省投入,并行计算可以以较低的投入完成任务
物理极限的约束,物理原件无法突破光速这个速度极限
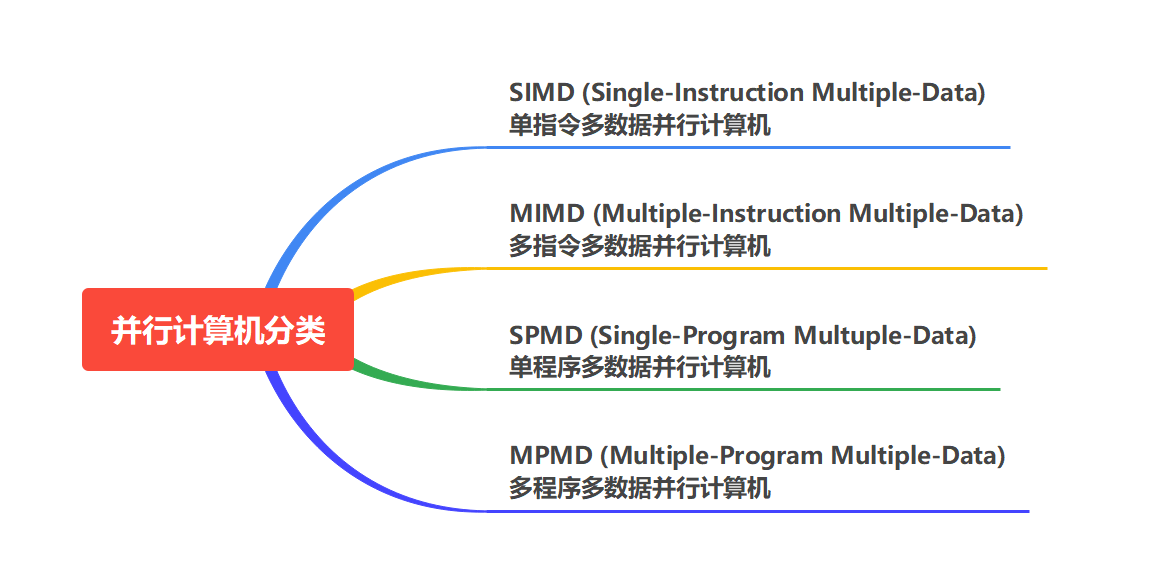
SIMD和MIMD
数组(向量)运算特别适合在SIMD并行机上执行,例如执行
MIMD 同时有多条指令对不同数据操作
SPMD和MPMD
SPMD是由多个地位相同的计算机或处理器组成的
MPMD并行计算机内计算机或处理器地位不同,擅长的工作不同所以可以将不同程序放到MPMD并行计算机上执行
数据的个数对并行计算机分类.png)
1.1.2储存方式
从物理上划分,有共享内存和分布式内存,分布共享内存。
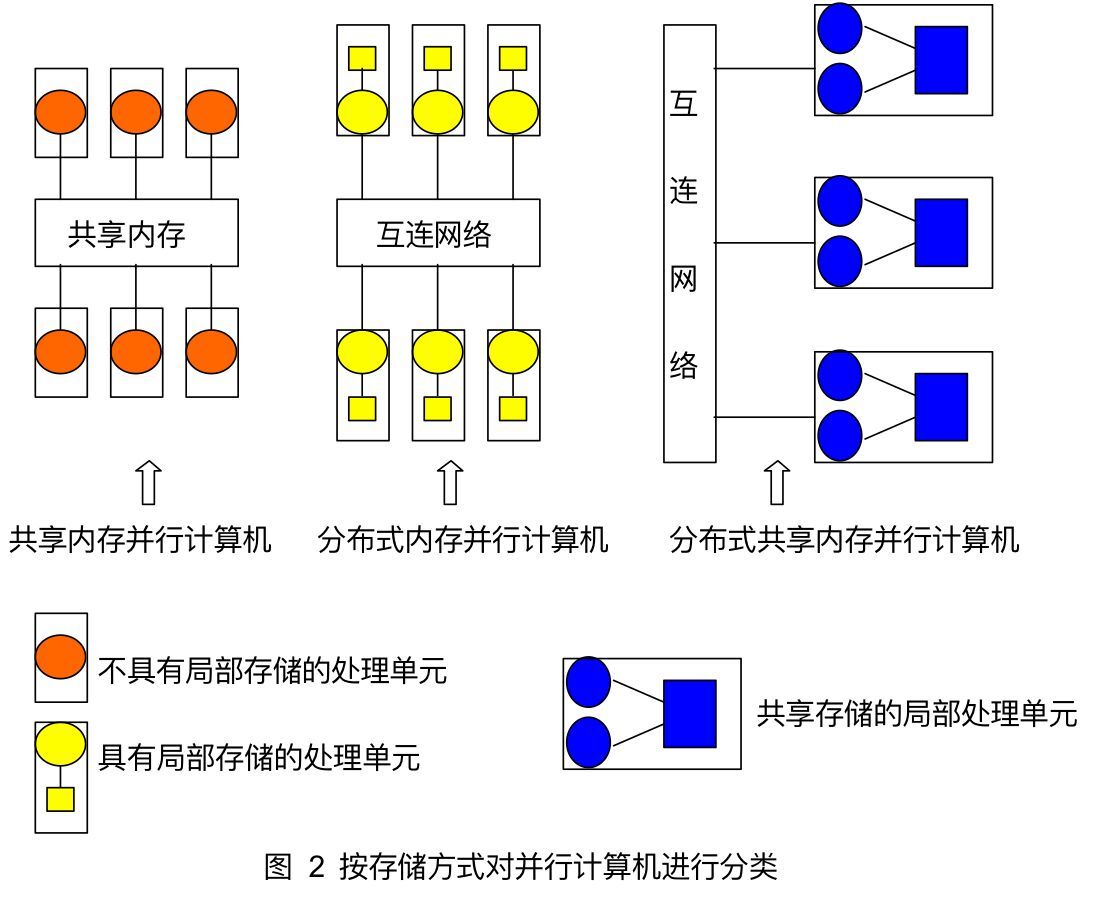
共享内存的并行计算机:各个处理单元通过对共享内存的访问来交换信息、协调各处理器对并行任务的处理。
分布式内存的并行计算机:各处理单元有自己独立的局部存储器,通过信息传递来交换信息,协调和控制各个处理器的执行。
分布式共享内存的并行计算机:机群计算大多采用这种形式的结构。
1.2物理问题在并行机上求解
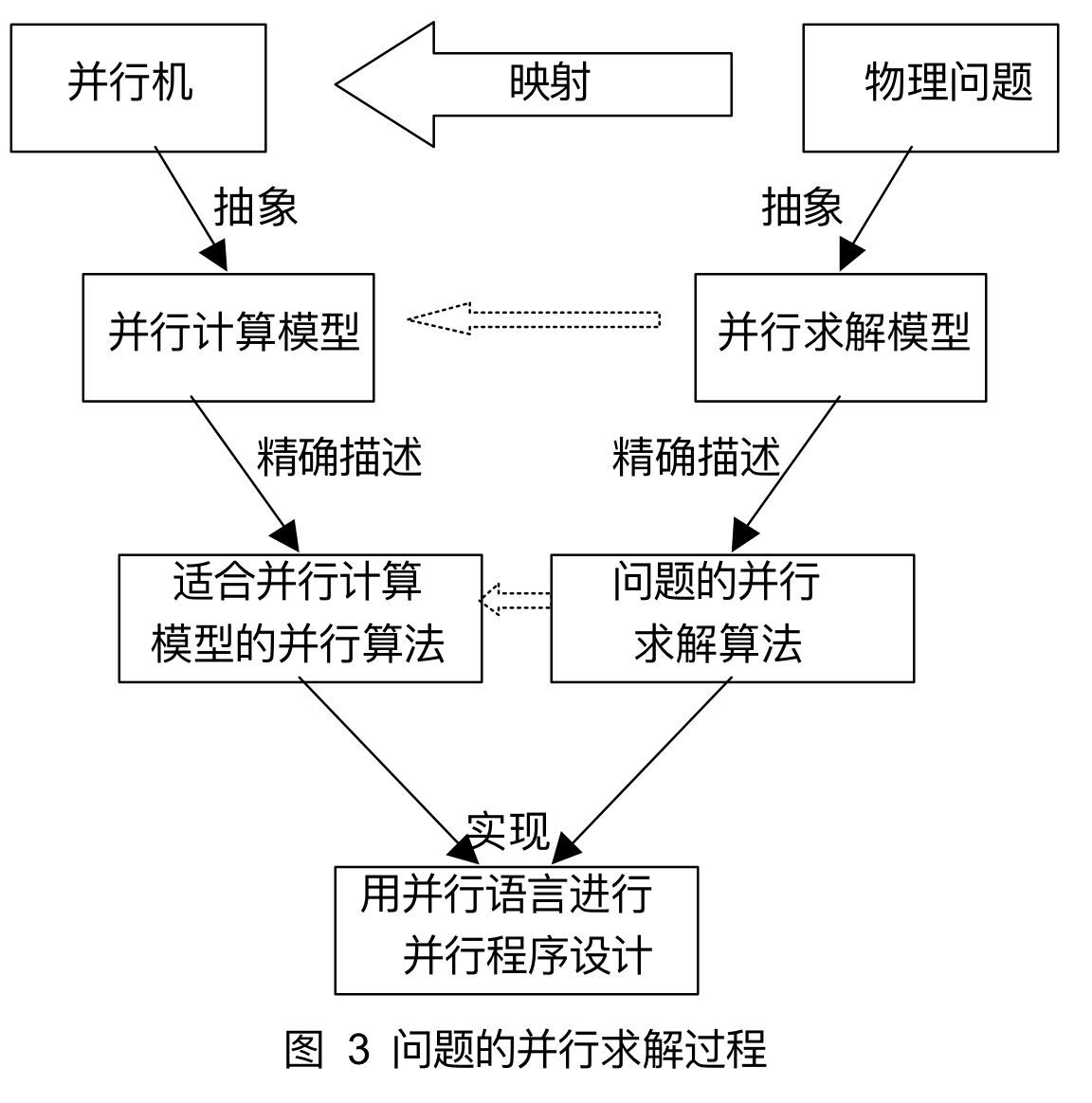
通过设计合适的并行算法来求解,一个物理问题在并行机上的映射。
第二章 并行编程模型与并行语言
2.1并行编程模型
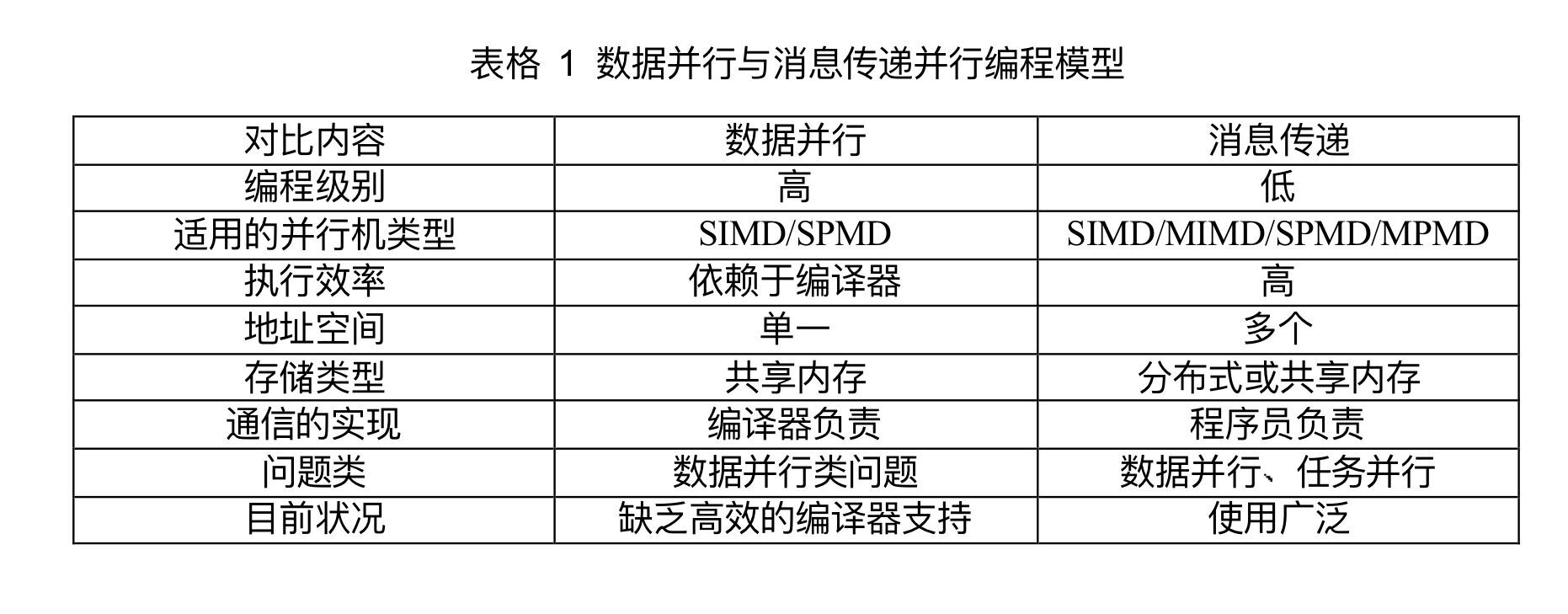
目前最重要的并行编程模型是数据并行和消息传递
数据并行编程模型,编程级别高,编程相对简单(比较封闭,不需要关心具体如何并行执行的),但是仅适用于数据并行问题
消息传递编程模型,编程级别低,但有更广泛的应用范围,一般应用于分布式内存的,也可适用于共享内存。
2.2并行语言
并行语言产生主要有三种方式:
- 设计全新的并行语言
- 扩展原来的串行语言的语法成分,使它支持并行特征
- 不改变串行语言,仅提供可调用的并行库
标注:一种重要的串行语言的扩充方式,对串行语言的并行扩充作为原来串行语言的注释,对于这样的并行程序,若用原来的串行编译器来编译,标注的并行扩充部分将不起作用,若使用扩充后的并行编译器来编译,编译器就会根据标注的要求,将原来的串行执行部分转化为并行执行。(本书介绍的MPI并行程序设计就是这种)
第三章 并行算法
3.1 并行算法分类
并行算法是一种具体、明确的解决方法和步骤。按照不同的划分方法,并行算法有多种分类。
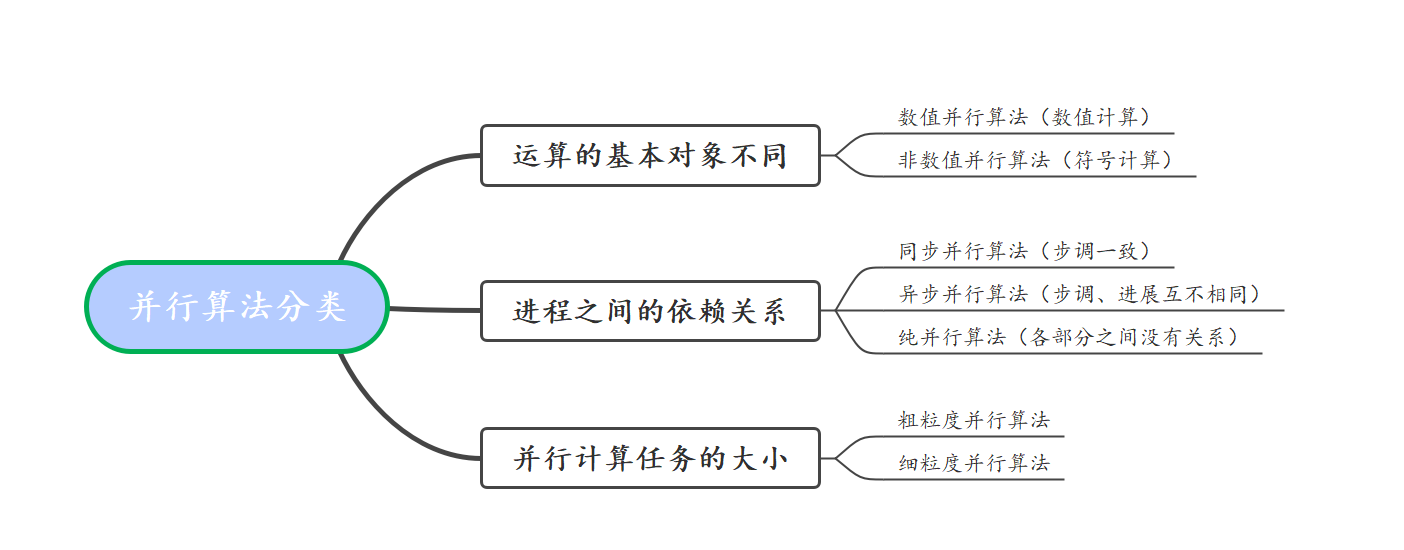
同步并行算法
任务各部分是同步向前推进的,有一个全局时钟(不一定是无力的)来控制各部分步伐
异步并行算法
各部分的步伐各不相同,它们根据计算过程的不同阶段决定等待、继续或终止
纯并行算法
最理想的情况,各部分之间可以尽快向前推进,不需要任何同步或等待,但是一般这样的问题是少见的
3.2并行算法的设计
并行算法根据问题类别的不同和并行机体系结构的特点产生出来的,好的算法要既能很好的匹配并行计算机硬件体系结构,又能反映问题内在的并行性。
- 对于SIMD并行计算机一般适合同步并行算法
- MIMD适合异步并行算法
- 对于新的SPMD和MPMD并行算法的思路和以前并行算法思路很不同
对于机群计算,很重要的原则就是设法加大计算时间相对于通信时间的比重,减少通信次数甚至以计算换通信。因为对于机群系统,一次通信的开销远大于一次计算的开销。因此对于机群计算并行粒度一般是大粒度或中粒度的。
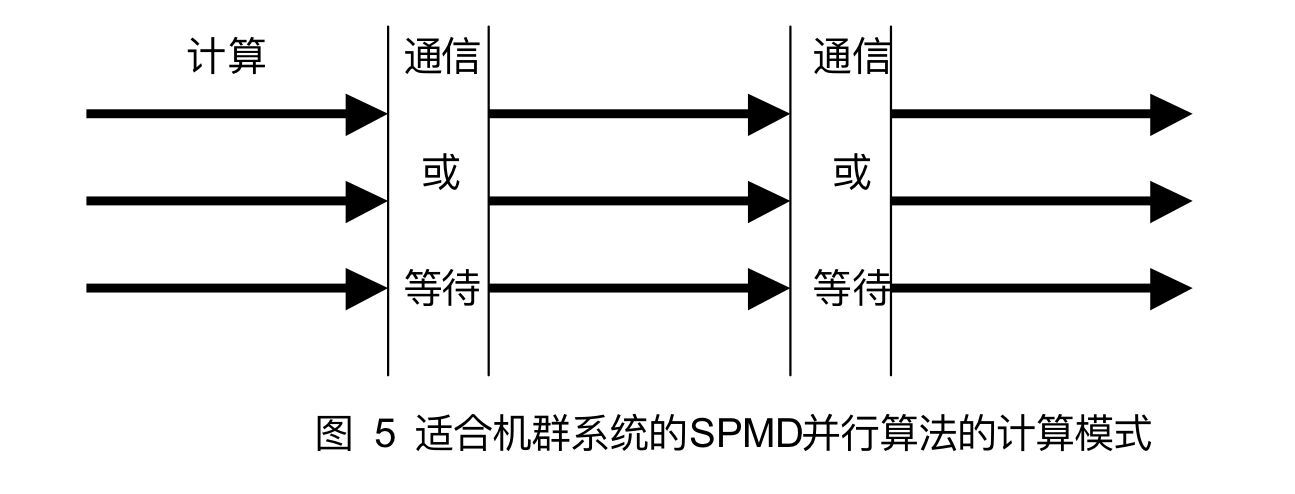
但是该设计模式没有考虑计算与通信的重叠,因此更理想的设计模式如下
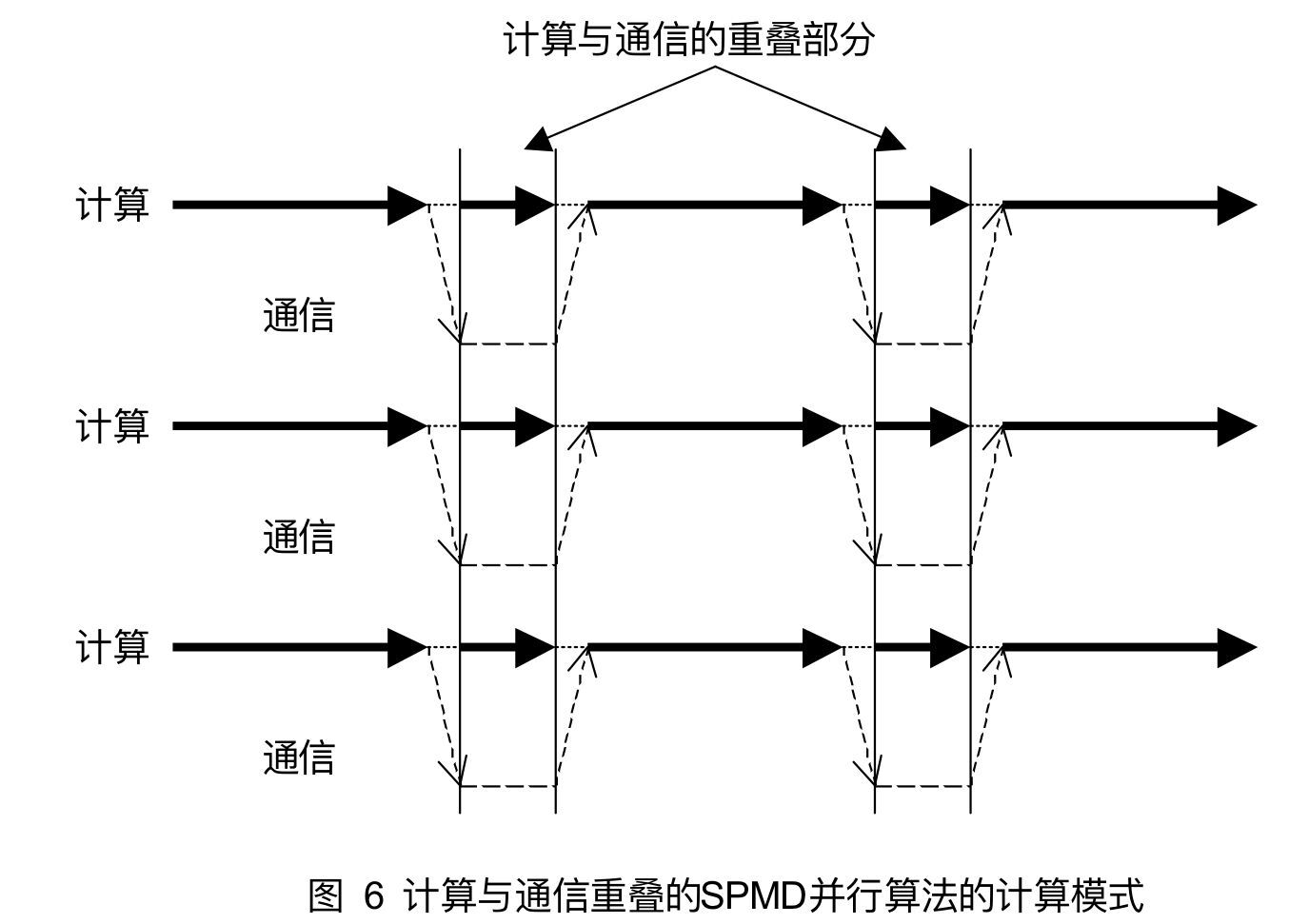
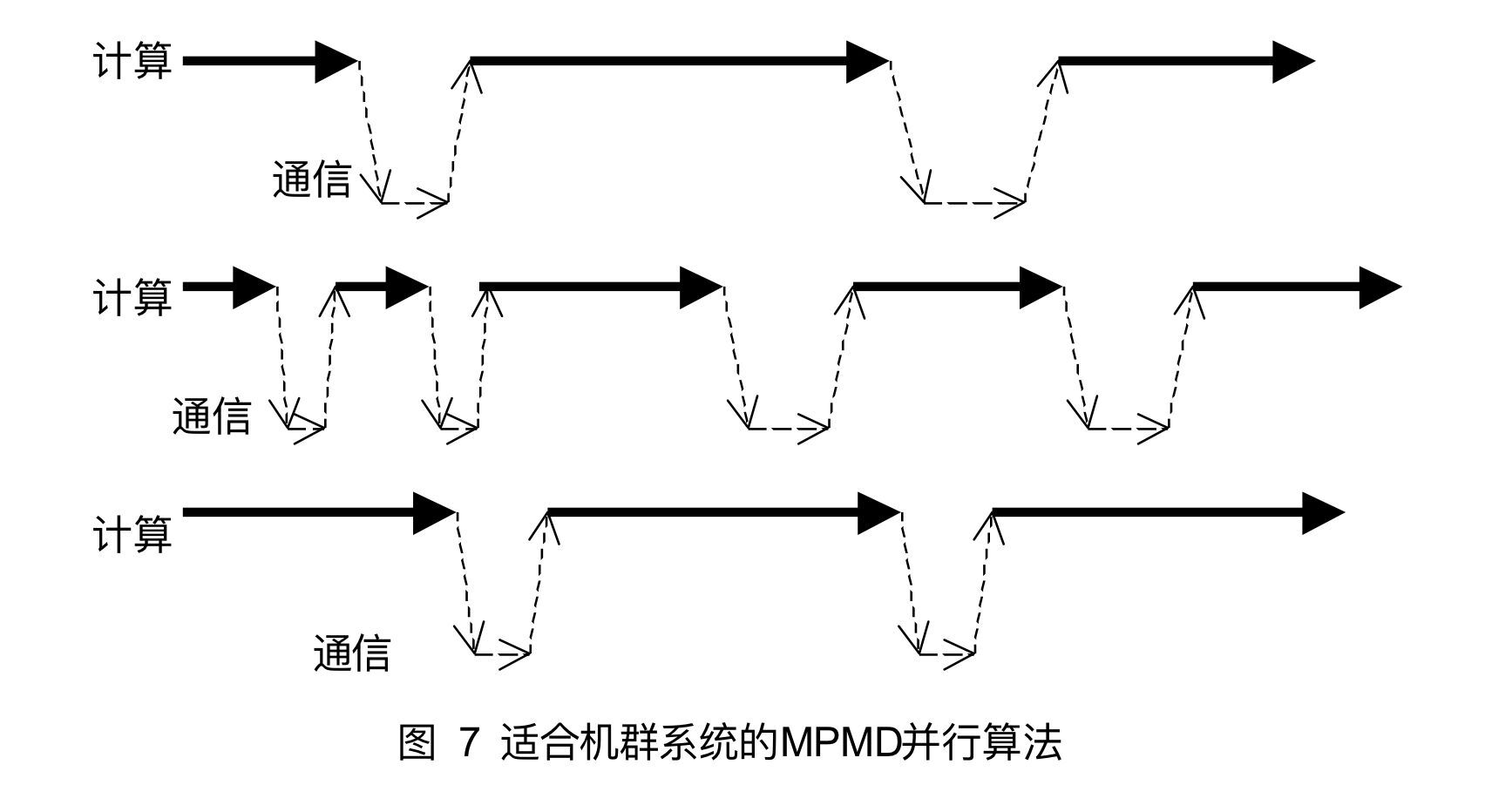
- 对于MPMD并行算法,各并行部分一般是异步执行的,因此只要能大大降低通信次数,增大计算相对于通信的比重,则该MPMD算法就可以取得较高的效率。
第二部分 基本的MPI并行程序设计
本部分包括MPI的基本介绍,一个相对完备的MPI子集,对等模式和主从模式MPI程序的编写,MPI的一个具体实现MPICH在Linux和NT操作系统下的安装和MPI程序的执行。
第四章 MPI简介
4.1 什么是MPI
- MPI是一个库,而不是一门语言。FORTRAN+MPI或C+MPI,看作是在原来串行语言基础上扩展后得到的并行语言。
- MPI是一种标准或规范的代表,而不特指某一个对它的具体实现。
- MPI是一种消息传递编程模型,并成为这种编程模型的代表和事实上的标准。MPI最终目的是服务于进程间通信。
4.2 MPI的目的
MPI的目标:
较高的通信性能
较好的程序可移植性
强大的功能
- 提供应用程序编程接口
- 提高通信效率。措施包括(避免存储器到存储器的多次重复拷贝,允许计算和通信的重叠等)
- 可在异构环境下提供实现
- 提供的接口方便C语言和Fortran77的调用
- 提供可靠的通信接口
- 定义的接口和现在已有的接口差别不能太大,但是允许扩展以提供更大的灵活性
- 定义的接口能在基本的通信和系统软件无重大改变时,在许多并行计算机生产商的平台上实现
- 接口设计是安全的
4.5 MPI的产生
MPICH是一种最重要的MPI实现,它可以免费从 http://www-unix.mcs.anl.gov/mpi/mpich 取得
CHIMP是另一个免费MPI实现,点击可跳转(目前打不开)
LAM也是免费的MPI实现,http://www.mpi.nd.edu/lam/download/
第五章 第一个MPI程序
5.1 MPI实现的“‘Hello World”
5.1.1 用FORTRAN77+MPI实现
- 第一部分(头文件)
MPI编写必须有FORTRAN头文件 mpif.h 对于Fortran90要将“include mpif.h”改为"use mpi"
- 第二部分(定义程序中所需要的于MPI有关的变量)
MPI_MAX_PROCESSOR_NAME是MPI预定义的宏,即某一MPI的具体实现中允许机器名字的最大长度,机器名放在变量processor_name中;整型变量myid和numprocs分别用来记录某一个并行执行的进程的标识和参加计算的进程的个数;namelen是实际得到的机器名字的长度;rc和ierr分别用来得到MPI过程调用结束后返回结果和可能的出错信息。
- 第三部分
MPI程序的开始和结束必须是MPI_INIT和MPI_FINALIZE,分别完成MPI程序的初始化和结束工作
- 第四部分(程序的程序体)
包括MPI过程调用语句和FORTRAN语句。
第六章 六个接口构成的MPI子集
6.1子集的介绍
6.1.1 MPI调用的参数说明
对于有参数的MPI调用,MPI首先给出一种独立于具体语言的说明,对各个参数的性质进行介绍,然后在给出相对于FORTRAN 77和C的原型说明,MPI对参数的说明有三种方式 IN, OUT, NOUT
- IN(输入):调用部分传递给MPI的参数,MPI除了使用该参数外不对这一参数做任何修改。
- OUT(输出):MPI返回给调用的部分的结果参数,该参数的初始值对MPI没有任何意义。
- NOUT(输入输出):调用部分首先将该参数传递给MPI,MPI对这一参数引用、修改后,将结果返回给外部调用,该参数的初始值和返回值都有意义。
6.1.2 MPI初始化
//独立语言说明MPI_INIT()//c语言说明int MPI_Init(int *argc, char ***argv)//fortran说明MPI_INIT(IERROR)INTEGER IERROR
6.1.3 MPI结束
xMPI_FINALIZE()
int MPI_Finalize(void)
MPI_FINALIZE(IERROR)INTEGER IERROR
6.1.4当前进程标识
xxxxxxxxxxMPI_COMM_RANK(comm, rank) IN comm //该进程所在的通信域(句柄) OUT rank //调用进程在comm中的标识号
int MPI_Comm_rank(MPI_Comm comm, int *rank)
MPI_COMM_RANK(COMM, RANK, IERROR) INTEGER COMM, RANK, IERROR这一调用返回调用进程在给定的通信域中的进程标识号,有了这一标识号,不同的进程就可以将自身和其他的进程区分开来,实现各进程的并行和协作。
6.1.5通信域包含的进程数
xxxxxxxxxxMPI_COMM_SIZE(comm, size) IN comm //通信域(句柄) OUT size //通信域comm内包含的进程数(整数)
int MPI_Comm_size(MPI_Comm comm, int *size)
MPI_COMM_SIZE(COMM, SIZE, IERROR) INTEGER COMM, SIZE, IERROR这一调用返回给定的通信域中所包含的进程的个数,不同的进程数通过这一调用得知在给定的通信域中一共有多少个进程在并行执行。
6.1.6消息发送
xxxxxxxxxxMPI_SEND(buf, count, datatype, dest, tag, comm)IN buf //发送缓冲区的起始地址IN count //将发送的数据的个数(非负整数)IN datatype //发送数据的数据类型(句柄)IN dest //目的进程标识号(整型)IN tag //消息标志(整型)IN comm //通信域(句柄)
int MPI_Send(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm) MPI_SEND(BUF, COUT, DATATYPE, DEST, TAG, COMM, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERROR
MPI_SEND将缓冲区内count个datatype数据类型的数据发送到目的进程(在通信域中标识号是dest),本次发送的消息标志是tag,使用这一标志(tag)能区分本次发送消息和本进程发送其他消息。
MPI_SEND操作指定的发送缓冲区是count个类型为datatype的连续数据空间组成,起始地址为buf。(以数据类型为单位指定消息的长度)
6.1.7消息接收
xxxxxxxxxxMPI_RECV(buf, count, datatype, source, tag, comm, status)OUT buf //接收缓冲区的起始地址IN count //最多可接受的数据个数(整型)IN datatype //接收数据的数据类型(句柄)IN source //接收数据的来源即发送数据的进程的进程标识号(整型)IN tag //消息标识,与相应的发送操作的表示相匹配相同(整型)IN comm //本进程和发送进程所在的通信域(句柄)OUT status //返回状态(状态类型) int MPI_RECV(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status) MPI_RECV(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS, IERROR) <type>BUF(*) INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS(MPI_STATUS_SIZE), IERROR从指定的进程source中接收消息,并且该消息的数据类型和消息标识号和本接收进程指定的datatype和tag一致,接收到的消息所包含的数据元素个数最多不超多count。
接收缓冲区由count个类型为datatype的连续空间组成,由datatype指定其指定类型,起始地址为buf。接收消息长度必须小于或等于接收缓冲区的长度,若超过而未截断会发生溢出错误。
6.1.8返回状态status
返回状态变量status用途很广,是MPI定义的一个数据类型,使用前需要分配空间。
C实现中,状态变量至少由三个域组成:MPI_SOURCE, MPI_TAG, MPI_ERROR。
在FORTRAN实现中,status是包含MPI_STATUS_SIZE个整型的数组,status(MPI_SOURCE)(发送数据的进程标识), status(MPI_TAT)(发送数据使用tag标识), status(MPI_ERROR)(接收操作返回的错误代码)
6.2 MPI预定义数据类型
MPI预定义数据类型与FORTRAN77数据类型的对应关系
| MPI预定数据类型 | FORTRAN77数据类型 |
|---|---|
| MPI_INTEGER | INTEGER |
| MPI_REAL | REAL |
| MPI_DOUBLE_PRECISION | DOUBLE PRECISION |
| MPI_COMPLEX | COMPLEX |
| MPI_LOGICAL | LOGICAL |
| MPI_CHARACTER | CHARACTER |
| MPI_BYTE | 无对应类型 |
| MPI_PACKED | 无对应类型 |
MPI预定义数据类型与C数据类型的对应关系
| MPI预定义数据类型 | C数据类型 |
|---|---|
| MPI_CHAR | signed char |
| MPI_SHORT | signed short int |
| MPI_INT | signed int |
| MPI_LONG | signed long int |
| MPI_UNSIGNED_CHAR | unsigned char |
| MPI_UNSIGNED_SHORT | unsigned short int |
| MPI_UNSIGNED | unsigned int |
| MPI_UNSIGNED_LONG | unsigned long int |
| MPI_FLOAT | float |
| MPI_DOUBLE | double |
| MPI_LONG_DOUBLE | long double |
| MPI_BYTE | 无对应类型 |
| MPI_PACKED | 无对应类型 |
6.3 MPI数据类型匹配和数据转换
6.3.1 MPI类型匹配规则
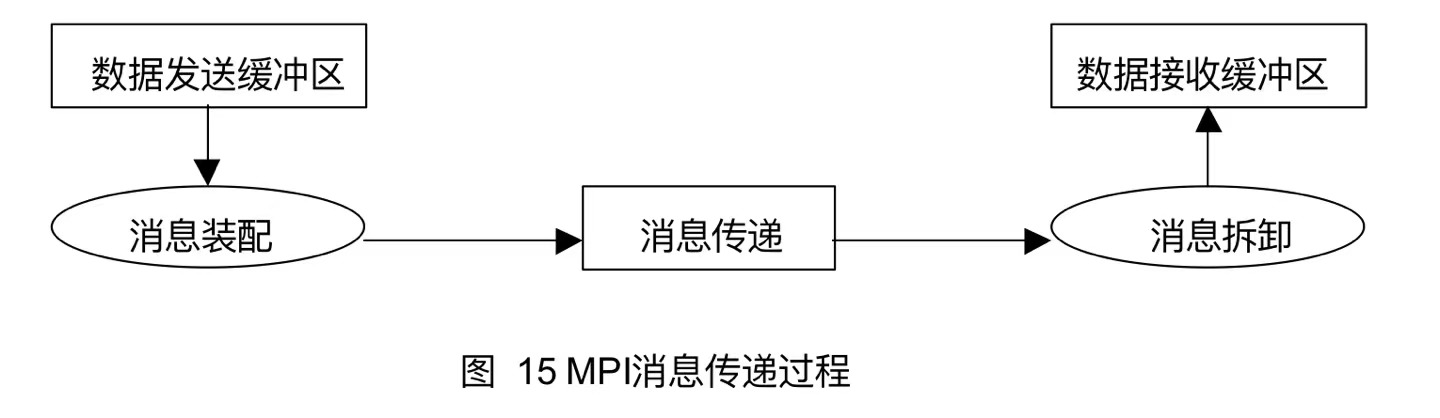
MPI的消息传递过程可以分为三个阶段:
- 消息装配:将发送数据从发送缓冲区中取出,加上消息信封等形成一个完整的消息。
- 消息传递:将装配好的消息从发送端传递到接收端。
- 消息拆卸:从接收到的消息中取出数据送入接收缓冲区。
宿主语言的类型和通信操作所指定的类型相匹配
发送方和接收方的类型相匹配
例外:MPI_BYTE用于不加修改的传送内存中二进制值,MPI_PACK用于数据的打包和解包。
归纳
- 有类型数据的通信:发送方和接收方均使用相同数据类型。
- 无类型数据的通信:发送方和接收方均以MPI_BYTE作为数据类型。
- 打包数据的通信:发送方和接收方均使用MPI_PACKED。
6.3.2 数据转换
- 数据类型的转换:改变一个值的数据类型。
- 数据表示的转换:改变一个值的二进制表示,比如高字节和低字节顺序的改变,浮点数从32位改成64位等。
MPI必须实现数据表示之间的转换,因为异构系统中不同系统数据内部表示往往是不同的。
6.4 MPI消息
6.4.1 MPI消息组成
MPI消息包括信封和数据两个部分
信封:发送或接收消息的对象及相关信息
信封
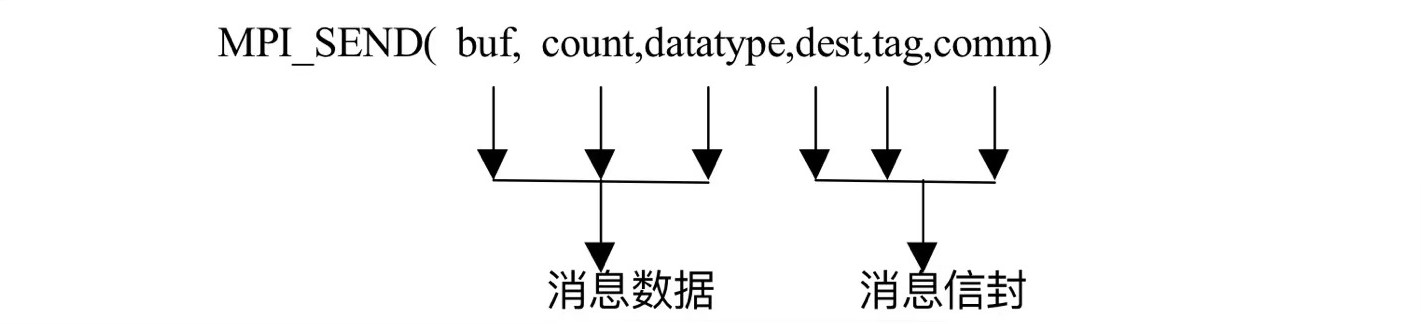
数据:本消息将要传递的内容
数据
tag标识:用来区分发送相同类型的数据给同一个接收者时区分二者。
6.4.2 任意源和任意标识
一个接受操作由消息的信封管理,只有信封与接收操作所指定的source,tag,comm相匹配,则能接收这个消息。在给source指定一个任意值 MPI_ANY_SOURCE 标识任何进程发送的消息都可以接收,但还应满足如 tag 匹配, 如果指定参数 MPI_ANY_TAG 则任意tag是可以接受的。
但是不能给comm指定任意值
6.4.3 MPI通信域
MPI通信域包括两个部分:
进程组:所有参加通信的进程的集合,若有N个进程,则从0-(N-1)编号。
通信上下文:提供一个相对独立的通信区域,不同的消息在不同的上下文中传递,不同上下文的消息互不干涉,区分通信区。
第七章 简单MPI程序示例
7.1 用 MPI 实现计时功能
MPI中时间函数
wtime
xxxxxxxxxxMPI_WTIME()
double MPI_Wtime(void)
DOUBLE_PRECISION_MPI_WTIME()返回一个用浮点数表示的秒数,它表示从过去某一时刻到调用时刻所经历的时间。这样如果需要对特定的部分进行计时,一般采取的方式是:
xxxxxxxxxxdouble starttime, endtime;...starttime = MPI_Wtime()//需要计时部分endtime = MPI_Wtime()printf("That tooks %f secondes\n", endtime-starttime)
wtick
xxxxxxxxxxMPI_WTICK()
double MPI_Wtick()
DOUBLE PRECISION MPI_WTICK()MPI_WTICK返回MPI_WTIME的精度,单位是秒,可以认为是一个时钟滴答所占用的时间。
7.2 获取机器的名字和MPI版本号
xxxxxxxxxxMPI_GET_PROCESSOR_NAME(name, resultlen) OUT name //当前进程运行机器名字 OUT resultlen //返回名字的长度
int MPI_Get_processor_name(char *name, int *resultlen)
MPI_GET_PROCESSOR_NAME(NAME, RESULTLEN, IERROR) CHARACTER *(*)NAME INTEGER RESULTLEN, IERROR运行时动态得到该进程所运行机器的名字。
xxxxxxxxxxMPI_GET_VERSION(VERSION, SUBVERSION) OUT vertion OUT subversion int MPI_Get_vertion(int *version, int *subversion)
MPI_GET_VERSION(VERSION, SUBVERSION, IERROR) INTEGER VERSION, SUBVERSION, IERROR返回MPI的主版本号version和次版本号subversion
7.3 是否初始化及错误退出
唯一一个可以在 MPI_INIT 之前的MPI 调用
xxxxxxxxxxMPI_INITALIZED(flag)OUT flag //MPI_INIT是否已执行标志
int MPI_Initialized(int *flag)
MPI_INITALIZED(FLAG, IERROR) LOGICAL FLAG INTEGER IERROR判断当前进程是否已经调用了 MPI_INIT ,若调用 flag=true, 否则反之。
如果在MPI程序过程中发现无法恢复的严重错误,因为只好退出MPI程序执行,MPI存在以下调用,并在退出时返回一个错误码。
xxxxxxxxxxMPI_ABORT(comm, errorcode) IN comm //退出进程所在的通信域 IN errorcode //返回到所嵌环境的错误码 int MPI_Abort(MPI_Comm comm, int errorcode)
MPI_ABORT(COMM, ERRORCODE, IERROR) INTEGER COMM, ERRORCODE, IERRORMPI_ABORT使通信域comm中的所有进程退出。本调用并不要求外部环境对错误码采取任何动作。
7.4 数据接力
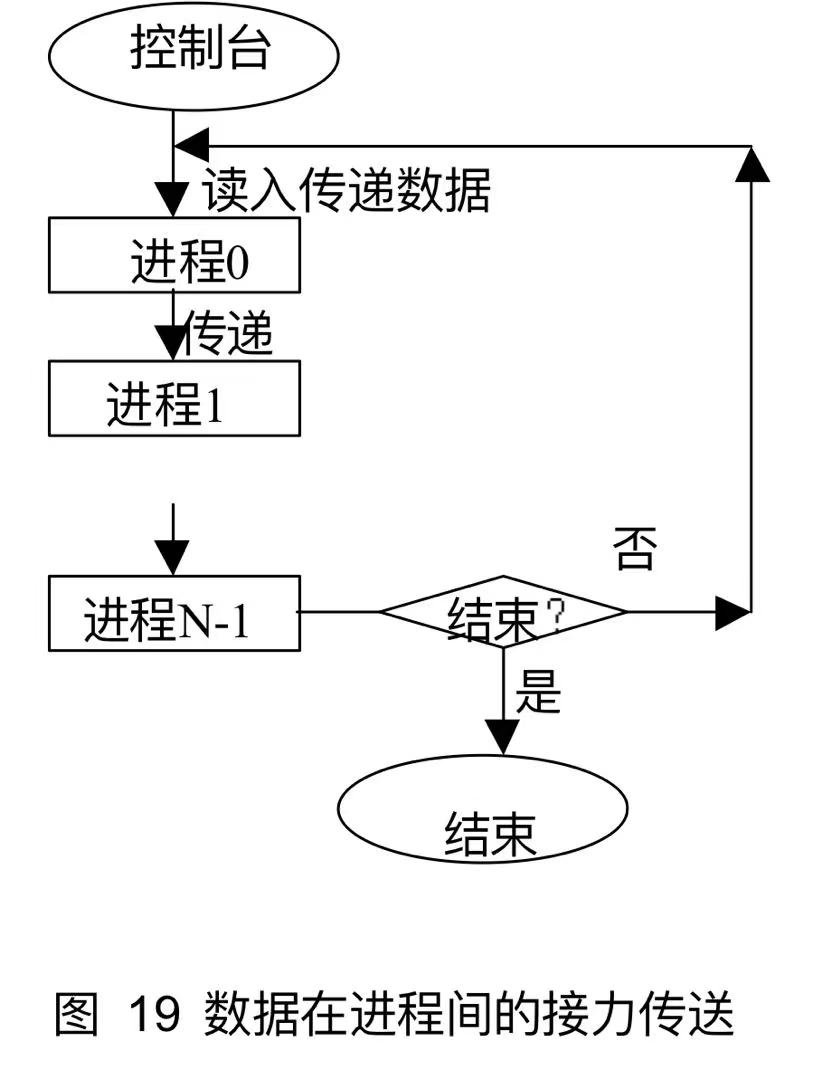
xxxxxxxxxx
int main(argc,argv)int argc;char **argv;{ int rank, value, size; MPI_Status status; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size);
//循环执行直到输入数为负数 do{ if(rank==0){ fprintf(stderr, "\nPlease give new value="); //进程为0读入要传递的数据 scanf("%d\n", &value); //读入value fprintf(stderr, "%d \n%d read <-<- (%d)\n",value,rank,value); if(size>1){ MPI_Send(&value, 1, MPI_INT, rank + 1, 0, MPI_COMM_WORLD); fprintf(stderr, "%d send (%d) ->-> %d\n",rank,value,rank+1); //若不少于一个进程,则向下一个进程传递该数据 } } else{ MPI_Recv(&value,1,MPI_INT,rank-1,0,MPI_COMM_WORLD,&status); //其他进程从前一个进程接收传递过来的数据 tag均为0 fprintf(stderr,"%d receive(%d) <-<- %d\n",rank,value,rank-1); if(rank<size-1){ MPI_Send(&value,1,MPI_INT,rank+1,0,MPI_COMM_WORLD); fprintf(stderr,"%d send (%d) ->-> %d\n",rank,value,rank+1); //若不是最后一个进程,则数据继续向后传递 } } MPI_Barrier(MPI_COMM_WORLD); //执行同步,加入它主要为了将前后两次数据传递分开,运行到此所有进程停止等待其他进程。不能同时传递。 }while(value>=0); MPI_Finalize();}
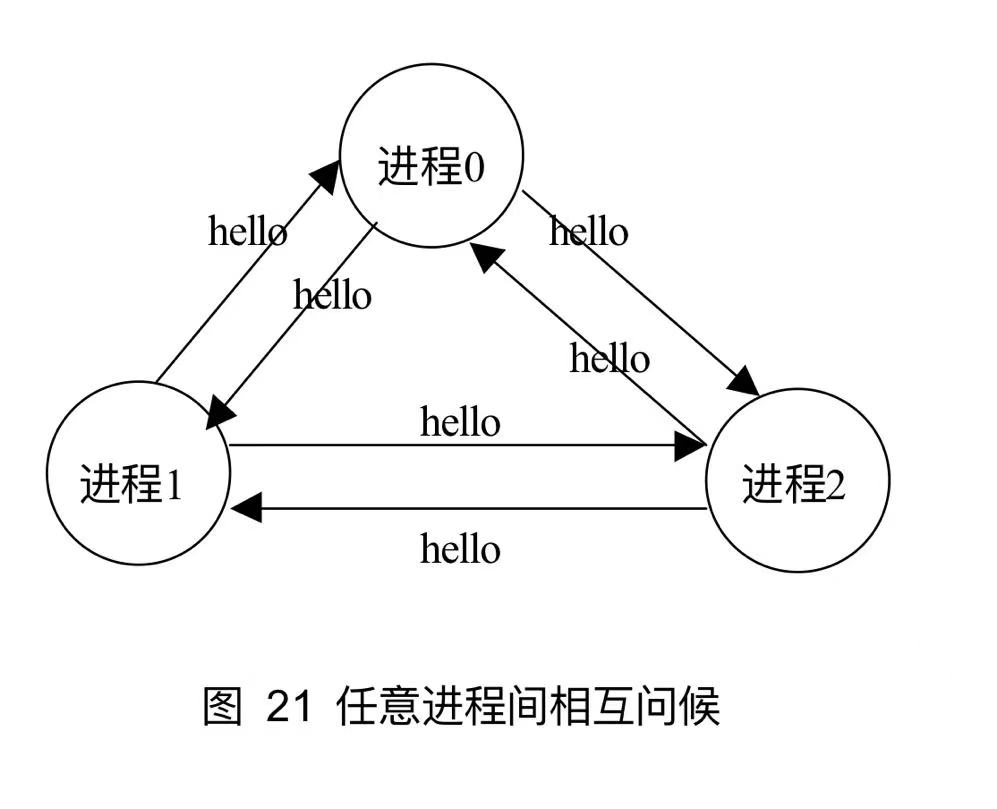
7.5 任意进程间相互问候
xxxxxxxxxx
void Hello(void);
int main(int argc, char *argv[]){ int me,option,namelen,size; char process_name[MPI_MAX_PROCESSOR_NAME]; MPI_Init(&argc,&argv); MPI_Comm_rank(MPI_COMM_WORLD,&me); MPI_Comm_size(MPI_COMM_WORLD,&size);
if(size<2){ fprintf(stderr,"systest requires at lease 2 process"); MPI_Abort(MPI_COMM_WORLD,1); } MPI_Get_processor_name(process_name,&namelen); fprintf(stderr,"Process %d is alive on %s \n",me,process_name); MPI_Barrier(MPI_COMM_WORLD); Hello(); MPI_Finalize();}
void Hello(void){ int nproc,me; int type = 1; int buffer[2],node; MPI_Status status; MPI_Comm_rank(MPI_COMM_WORLD,&me); MPI_Comm_size(MPI_COMM_WORLD,&nproc);
if(me == 0){ printf("\nHello test from all to all\n"); fflush(stdout); } for(node = 0;node<nproc;node++){ //循环对每一个进程进行问候 if(node != me){ //得到一个和自身不同的进程标识 buffer[0]=me;//自身标识放入消息 buffer[1]=node;//被问候的进程标识放入消息中 MPI_Send(buffer,2,MPI_INT,node,type,MPI_COMM_WORLD); MPI_Recv(buffer,2,MPI_INT,node,type,MPI_COMM_WORLD,&status); if((buffer[0]!=node)||(buffer[1]!=me)){ //接收到消息不是问候自己或者自己问候别人,则出错 (void)fprintf(stderr,"Hello:%d!=%d or %d!=%d\n",buffer[0],node,buffer[1],me); printf("Mismatch on hello process ids; node=%d\n",node); } printf("Hello from %d to %d\n",me,node); //打印出问候成功信息 fflush(stdout); } }}
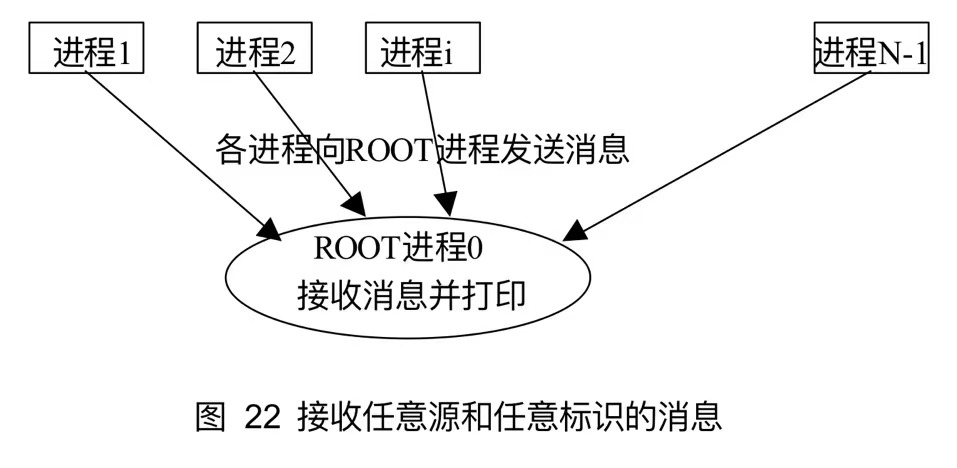
7.6 任意源和任意标识的使用
通过使用任意源和任意tag标识,使得该接收操作可以接收任何进程以任何标识发送给本进程的数据,但是数据类型必须一致。
xxxxxxxxxx
int main(argc,argv)int argc;char**argv;{ int rank,size,i,buf[1]; MPI_Status status; MPI_Init(&argc,&argv); MPI_Comm_rank(MPI_COMM_WORLD,&rank); MPI_Comm_size(MPI_COMM_WORLD,&size);
if(rank==0){ for(int i=0;i<100*(size-1);i++){ MPI_Recv(buf,1,MPI_INT,MPI_ANY_SOURCE,MPI_ANY_TAG,MPI_COMM_WORLD,&status); printf("Msg=%d from %d with tag %d\n",buf[0],status.MPI_SOURCE,status.MPI_TAG); } } else{ for(i=0;i<100;i++){ buf[0]=rank+i; MPI_Send(buf,1,MPI_INT,0,i,MPI_COMM_WORLD); } } MPI_Finalize();}
7.7 编写安全的MPI程序
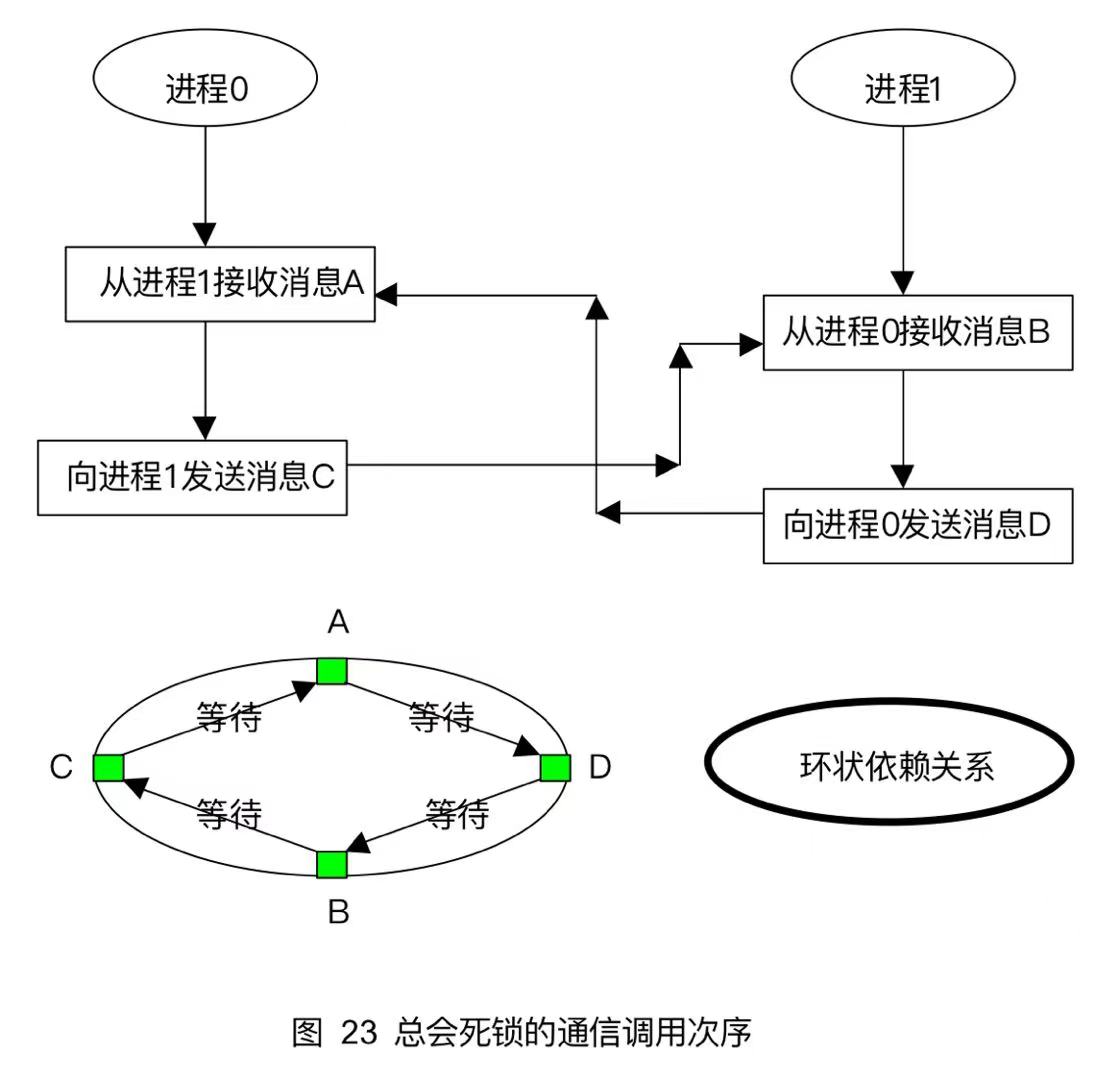
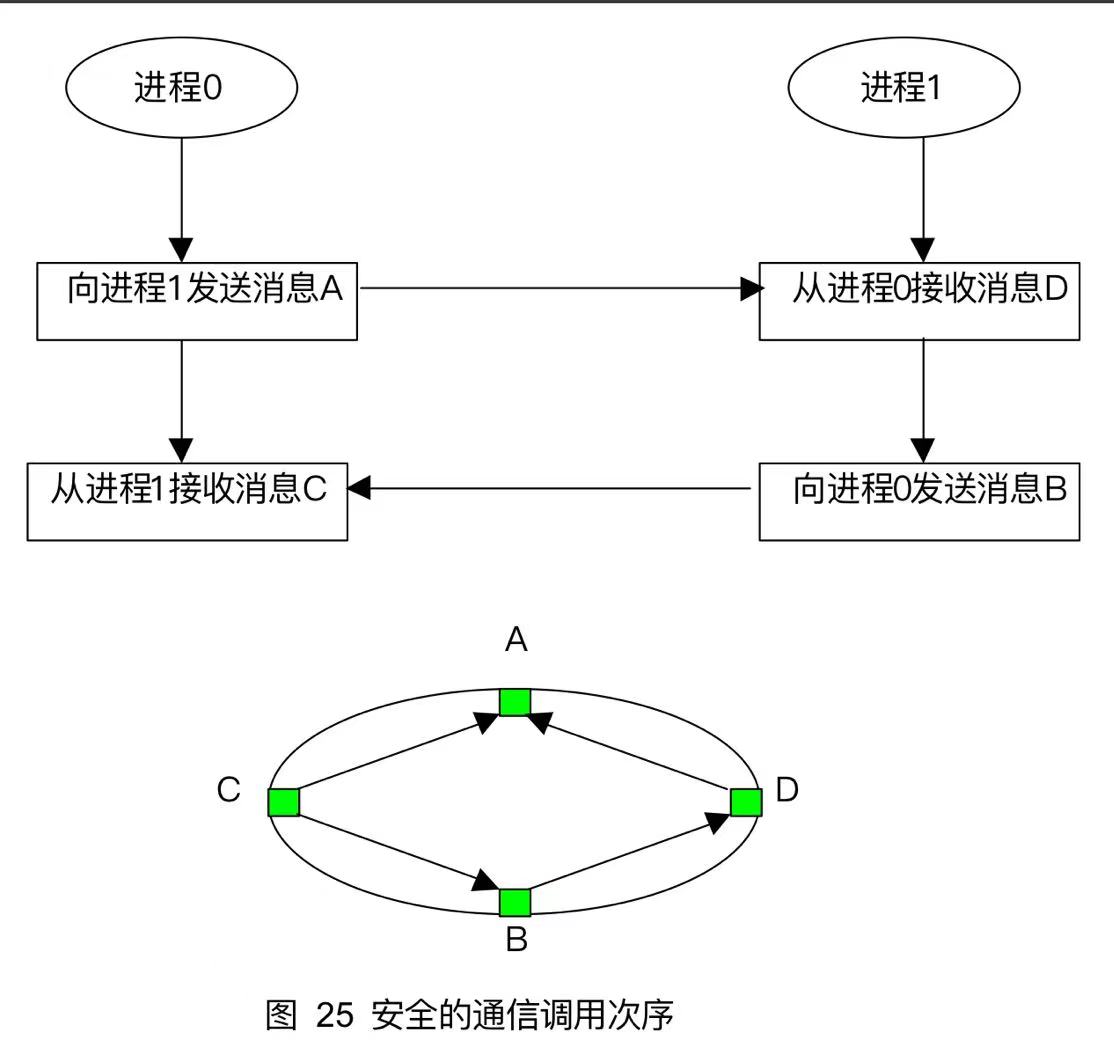
编写MPI程序,如果通信调用顺序使用不当,容易造成死锁,如下程序会死锁。
xxxxxxxxxx
int main(int argc,char*argv[]){ int rank,size,recvbuf[1],sendbuf[1]; recvbuf[0]=1;sendbuf[0]=1; MPI_Status status; MPI_Init(&argc,&argv); MPI_Comm_rank(MPI_COMM_WORLD,&rank); if(rank==0){ MPI_Recv(recvbuf,1,MPI_INT,1,0,MPI_COMM_WORLD,&status); MPI_Send(sendbuf,1,MPI_INT,1,2,MPI_COMM_WORLD); } else{ MPI_Recv(recvbuf,1,MPI_INT,0,2,MPI_COMM_WORLD,&status); MPI_Send(sendbuf,1,MPI_INT,0,0,MPI_COMM_WORLD); } MPI_Finalize();}该程序会形成如图所示的依赖循环,所有进程操作都等待,形成死锁,无法执行。
如果换成先发送,则会造成不安全的情况。
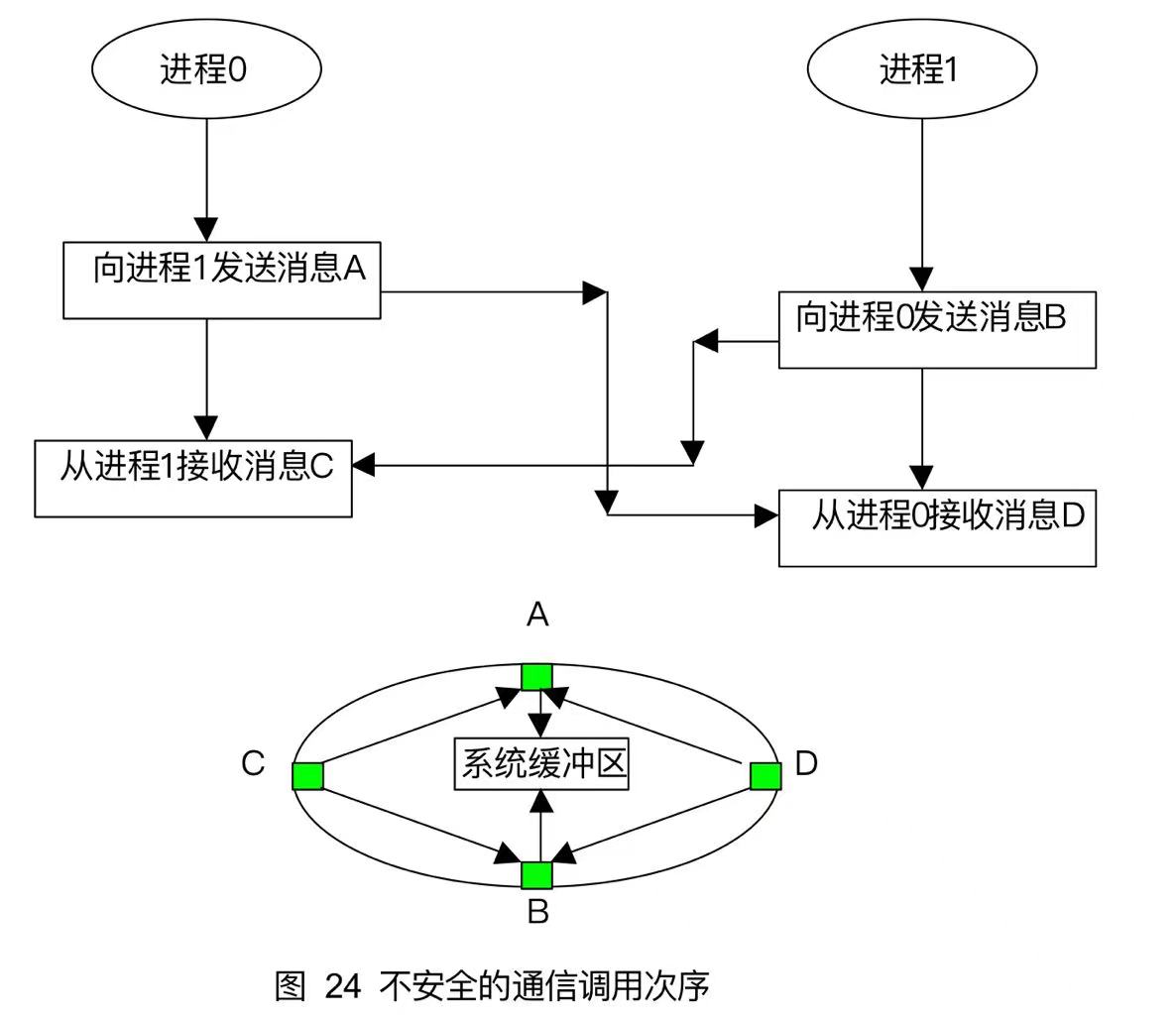
xxxxxxxxxx//运行有结果是因为系统缓冲区并未不足,但是实际在大型程序中并不安全int main(int argc,char*argv[]){ int rank,size,recvbuf[1],sendbuf[1]; MPI_Status status; MPI_Init(&argc,&argv); MPI_Comm_rank(MPI_COMM_WORLD,&rank); if(rank==0){ sendbuf[0]=1; MPI_Send(sendbuf,1,MPI_INT,1,2,MPI_COMM_WORLD); MPI_Recv(recvbuf,1,MPI_INT,1,0,MPI_COMM_WORLD,&status); printf("rank %d receive %d",rank,recvbuf[0]); } if(rank==1){ sendbuf[0]=0; MPI_Send(sendbuf,1,MPI_INT,0,0,MPI_COMM_WORLD); MPI_Recv(recvbuf,1,MPI_INT,0,2,MPI_COMM_WORLD,&status); printf("rank %d receive %d",rank,recvbuf[0]); } MPI_Finalize();}
正确的调用应该进程0与进程1接收与发送操作错开。
第八章 MPI 并行程序的两种基本模式
本章介绍MPI的两种最基本的并行程序设计模式吗对等模式和主从模式。
对等模式的MPI程序,本章是通过一个典型例子——jacobi迭代来逐步讲解的,并将每一种具体的实现都和特定的MPI增强功能结合起来。
主从模式的MPI程序通过几个简单的例子讲解主从进程功能的划分和主从进程之间的交互作用。
MPI程序一般是SPMD(单程序多数据并行机)也可以编写MPMD(多程序多数据并行机),但所有的MPMD都可以用SPMD来表达。
8.1 对等模式的MPI程序设计
8.1.1 问题描述——Jacobi迭代
Jacobi迭代得到的新值是原来旧值点相邻数值点的平均。
Jacobi迭代的局部性很好,可以取得很高的并行性,是并行计算中常见的一个例子。将参加迭代的数据按块分割后,各块之间除了相邻的元素需要通信外,在各块的内部可以完全独立的并行计算,随着计算规模的扩大,通信的开销相对于计算来说比例会降低,这将更有利于提高并行效果。
8.1.2 用MPI程序实现Jacobi迭代
为了并行求解,将参加迭代的数据按列进行分割。
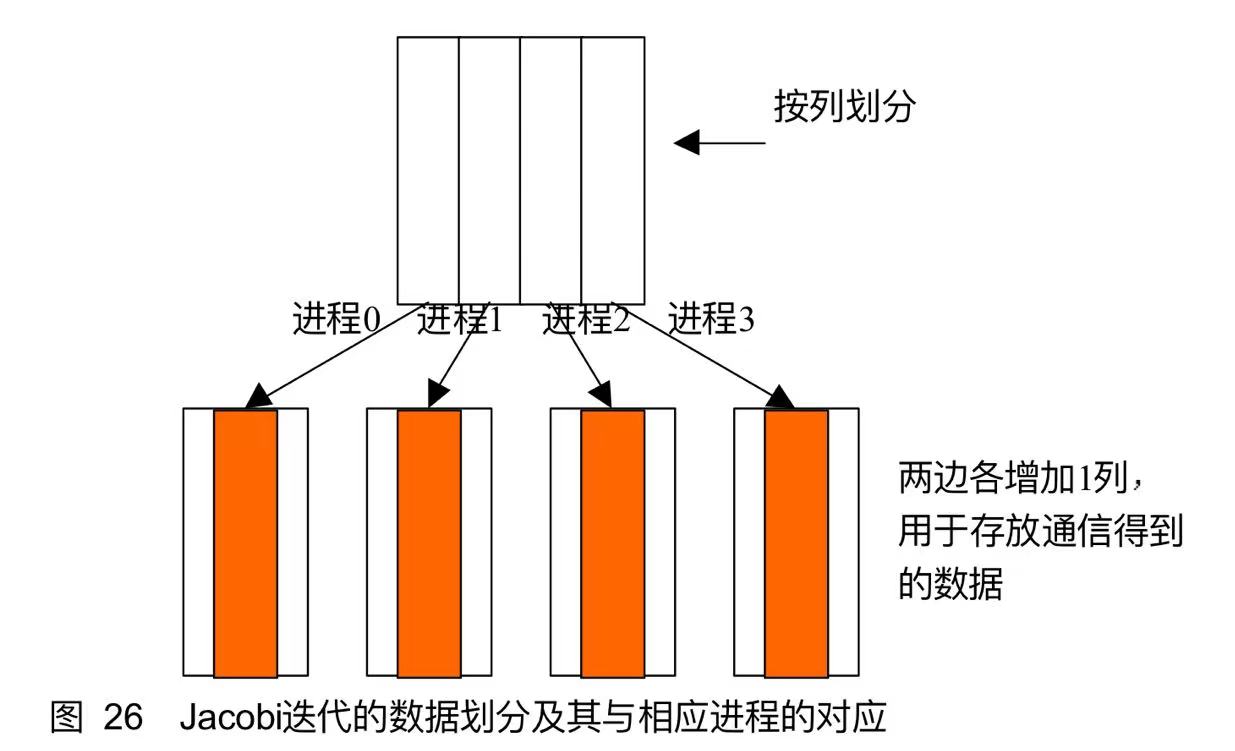
假设需要迭代的数据是M
由于迭代过程中,边界点新值的计算需要相邻边界其他块的数据,因此在每一个数据块的两侧又各增加1列数据空间,用于存放从相邻数据块通信得到的数据。这样原来每个数据块的大小从M * N扩大到 M * (N+2), 进程0和进程3的数据块只需扩大一块即可满足通信的要求,但这里为了编程的方便和形式的一致,在两边多增加了数据块。
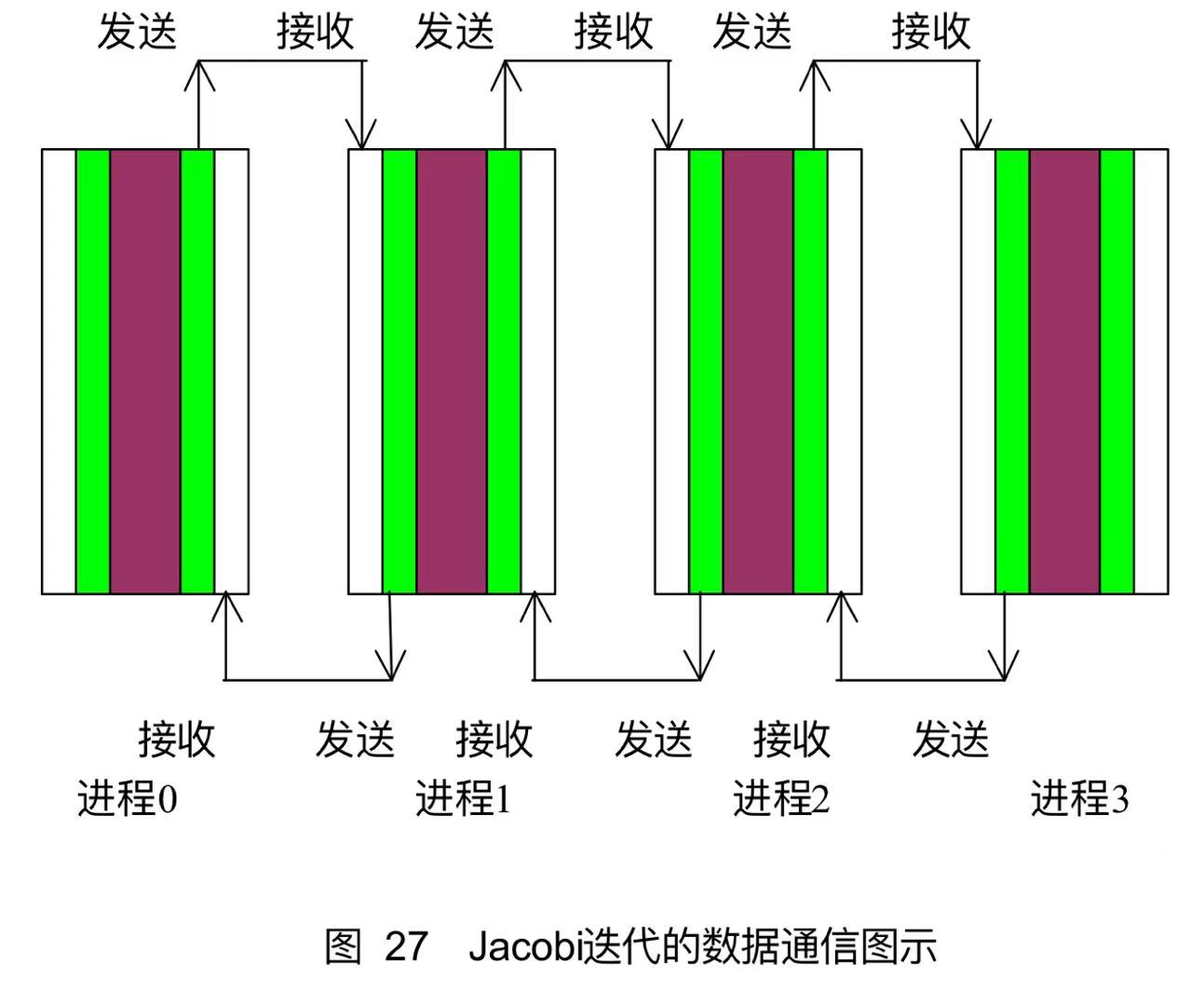
计算和通信过程如下:
- 首先对数组赋初值,边界赋为8,内部赋为0,不同的进程赋值方式不同(两个内部块相同,但内部块和两个外部块两两互不相同)。
- 然后开始Jacobi迭代,迭代前,每个进程都需要从相邻的进程得到数据块,同时每一个进程也都需要向相邻的进程提供数据块。
- 由于每一个新迭代点的值是由相邻点的旧值得到,所以引入一个中间数组,记录临时得到的新值,一次迭代完后再统一操作。
xxxxxxxxxx//fortran语言和c语言在数组上物理实际存储顺序不一样,所以对于Jacobi迭代二者数据存储需要旋转九十度
//修改使用MPI_Sendrecv实现
int main(int argc,char *argv[]){ int totalsize=16,mysize=totalsize/4,steps=10; int n,myid,numprocs,i,j,rc; double a[6][16],b[6][16]; int begin_col,end_col; MPI_Status status;
MPI_Init(&argc,&argv); MPI_Comm_rank(MPI_COMM_WORLD,&myid); MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
printf("Process %d/%d is alive\n",myid+1,numprocs); memset(a,0,sizeof(a));
// 数据块初始化 if(myid==0){ for(int i=0;i<totalsize;i++){ a[1][i]=8.0; //非通信区域上边边界赋值8 } } if(myid==3){ for(int i=0;i<totalsize;i++){ a[mysize][i]=8.0; //非通信区域下边边界赋值8 } } for(int i=0;i<mysize+2;i++){ a[i][0]=8.0;a[i][totalsize-1]=8.0; //上下边界赋值为8 }
//Jacobi迭代部分 for(int n=0;n<steps;n++){ //steps是10 //原始模式 // if(myid<3){ // MPI_Recv(&a[mysize+1][0],totalsize,MPI_DOUBLE,myid+1,10,MPI_COMM_WORLD,&status); //从下侧邻居得到数据 // } // if(myid>0){ // MPI_Send(&a[1][0],totalsize,MPI_DOUBLE,myid-1,10,MPI_COMM_WORLD); //向上侧邻居发送数据 // } // if(myid<3){ // MPI_Send(&a[mysize][0],totalsize,MPI_DOUBLE,myid+1,10,MPI_COMM_WORLD); //向下侧邻居发送数据 // } // if(myid>0){ // MPI_Recv(&a[0][0],totalsize,MPI_DOUBLE,myid-1,10,MPI_COMM_WORLD,&status); //从上侧接收数据 // }
//捆绑发送模式 //先从上向下发送 if(myid==0){ MPI_Send(&a[mysize][0],totalsize,MPI_DOUBLE,myid+1,10,MPI_COMM_WORLD); } else if(myid==3){ MPI_Recv(&a[0][0],totalsize,MPI_DOUBLE,myid-1,10,MPI_COMM_WORLD,&status); } else { MPI_Sendrecv(&a[mysize][0],totalsize,MPI_DOUBLE,myid+1,10,&a[0][0],totalsize,MPI_DOUBLE,myid-1,10,MPI_COMM_WORLD,&status); } //在从下向上发送 if(myid==0){ MPI_Recv(&a[mysize+1][0],totalsize,MPI_DOUBLE,myid+1,10,MPI_COMM_WORLD,&status); } else if(myid==3){ MPI_Send(&a[1][0],totalsize,MPI_DOUBLE,myid-1,10,MPI_COMM_WORLD); } else { MPI_Sendrecv(&a[1][0],totalsize,MPI_DOUBLE,myid-1,10,&a[mysize+1][0],totalsize,MPI_DOUBLE,myid+1,10,MPI_COMM_WORLD,&status); }
begin_col=1; end_col=mysize; if(myid==0){ begin_col=2; } if(myid==3){ end_col=mysize-1; }
for(j=begin_col;j<=end_col;j++){ for(i=1;i<=totalsize-2;i++){ b[j][i]=(a[j+1][i]+a[j-1][i]+a[j][i+1]+a[j][i-1])*0.25; //每个值是周围平均值 } } for(int j=begin_col;j<=end_col;j++){ for(int i=1;i<=totalsize-2;i++){ a[j][i]=b[j][i]; } } }
// printf("process %d :\n",myid); for(int j=begin_col;j<=end_col;++j){ for(int i=1;i<totalsize-1;++i){ printf("%lf ",a[j][i]); } printf("\n"); } MPI_Finalize();}
8.1.3 捆绑发送接收实现Jacobi迭代
捆绑发送接收能用一条语句实现,发送与接收的操作,允许从同一个源接收或发送给这个源,由通信系统来协调,系统优化通信次序,避免由于次序错误产生的死锁。
xxxxxxxxxxMPI_SENDRECV(sendbuf, sendcount, sendtype, dest, sendtag, recvbuf, recvcount, recvtype, source, source, recvtag, comm, status) IN sendbuf //发送缓冲取起始地址 IN sendcount //发送数据个数 IN sendtype //发送数据的数据类型 IN dest //目标进程标识 IN sendtag //发送数据标识 OUT recvbuf //接收缓冲区初始地址 IN recvcount //最大接收数据个数 IN recvtype //接收数据的数据类型 IN source //源进程标识 IN recvtag //接收消息标识 IN comm //通信域 OUT status //返回的状态 int MPI_Sendrecv(void *sendbuf,int sendcount,MPI_Datatype sendtype,int dest,ind sendtag,void *recvbuf,int recvcount,MPI_Datatype recvtype, int source,int recvtag,MPI_Comm comm,MPI_Status *status)
MPI_Sendrecv_replace与MPI_Sendrecv类似但是该函数只有一个缓冲区域,当消息发送出去后,再接收消息替换该缓冲区域的消息,能节省一个区域的空间。
xxxxxxxxxxMPI_SENDRECV_REPLACE(buf,count,datatype,dest,sendtag,source,recvtag,comm,status) INOUT buf //发送和接收的缓冲区 IN count //发送和接收缓冲区中的数据个数 IN datatype //发送和接收缓冲区中的数据的数据类型 IN dest //目标进程标识 IN sendtag //发送消息标识 IN source //源进程标识 IN recvtag //接收消息标识 IN comm //发送进程和接收进程所在的通信域 OUT status //状态目标 int MPI_Sendrecv_replace(void *buf,int count,MPI_Datatype datatype,int dest,int sendtag,int source,int recvtag,MPI_Comm comm,MPI_Status *status)
8.1.4引入虚拟进程后Jacobi迭代
虚拟进程(MPI_PROC_NULL)是不存在的假想进程,作用是充当真实进程通信的目的或源。如同执行了一个空操作。
8.2主从模式的MPI程序设计
8.2.1 矩阵向量乘
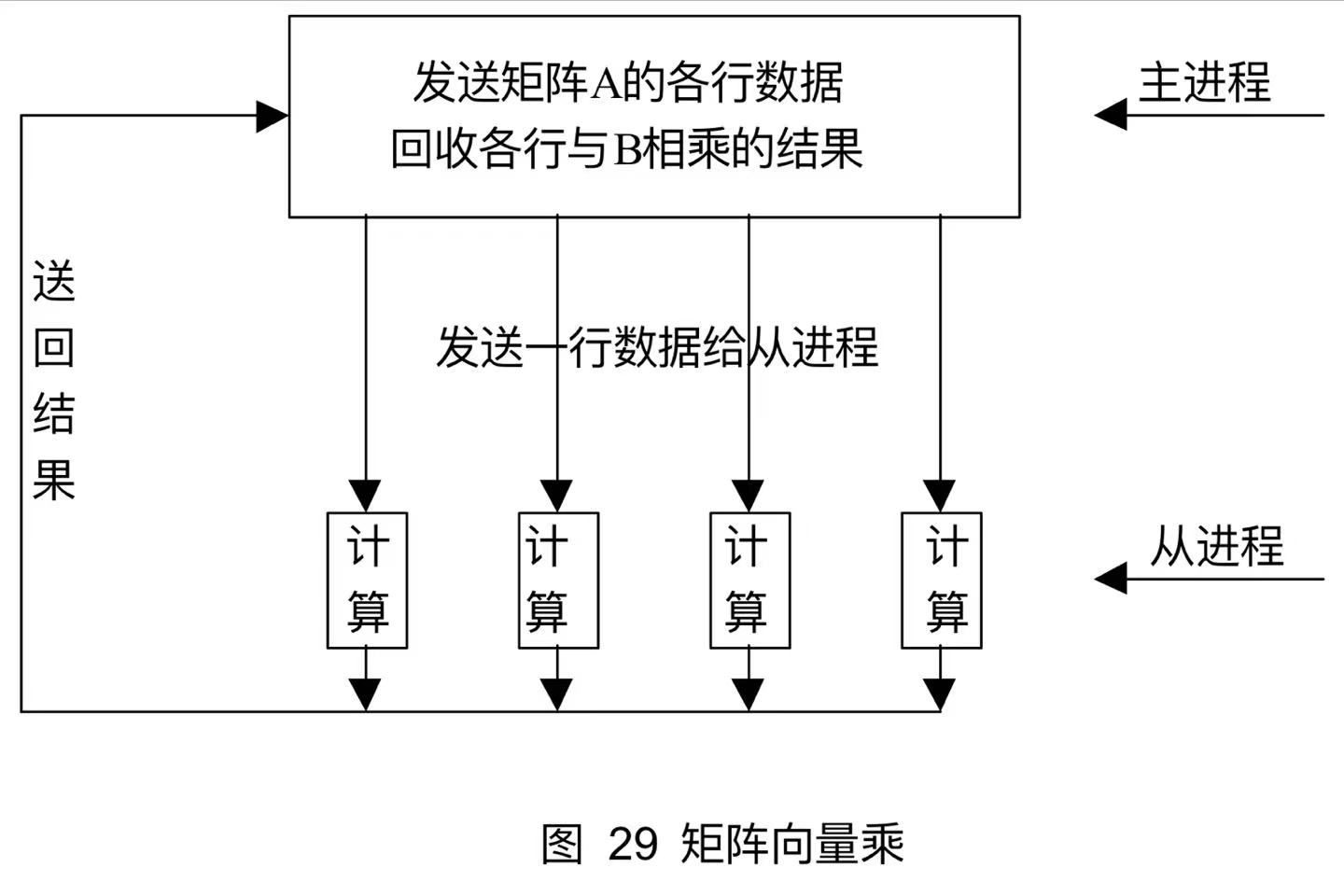
计算矩阵
8.2.2主进程打印各从进程的消息
分别实现按照从进程结点编号的大小一次打印,或以任意顺序打印。
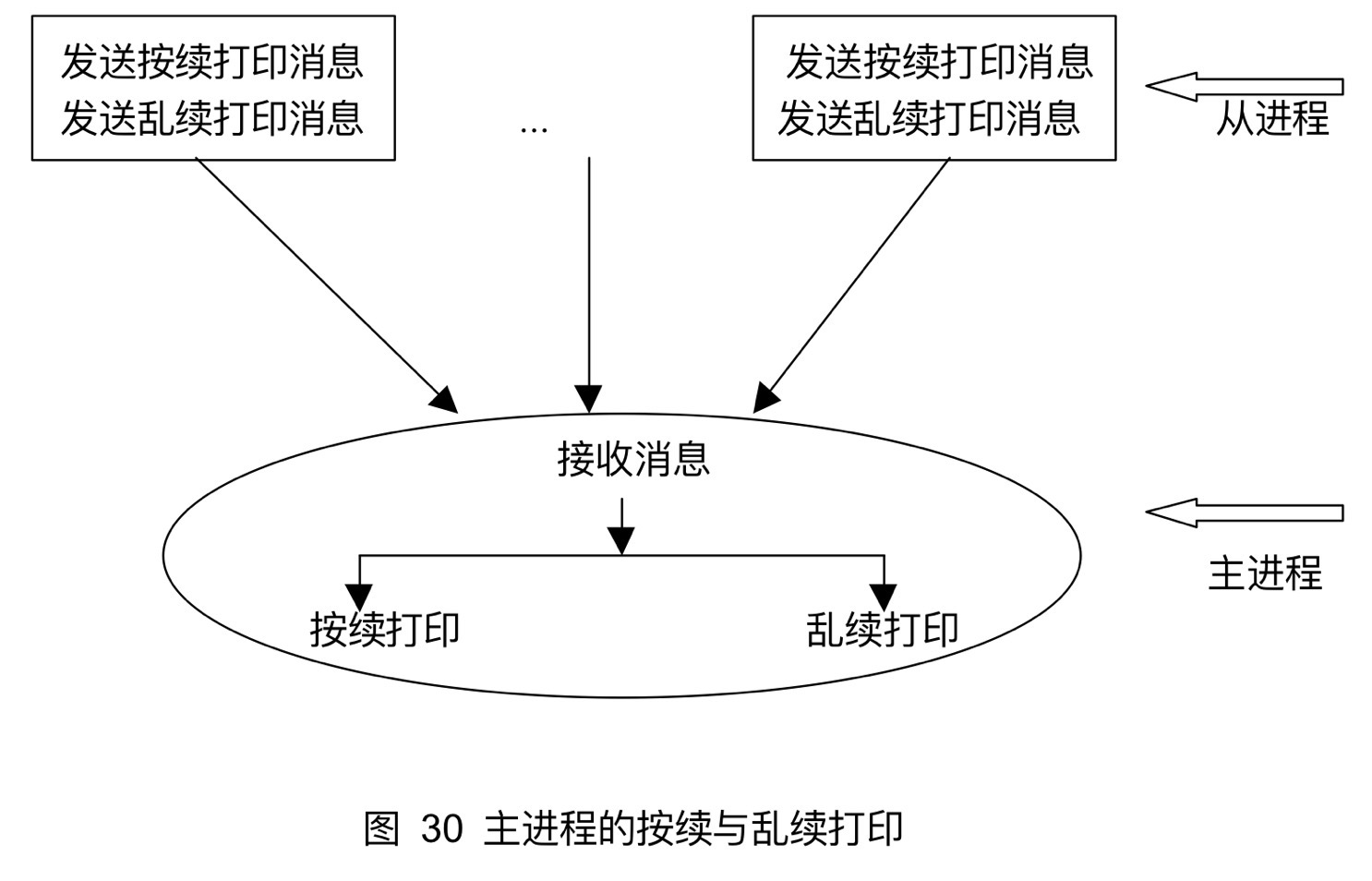
第九章 不同通信模式MPI并行程序的设计
还有几种其他的通信模式

这几种通信模式主要根据以下不同的情况来区分:
- 是否需要对发送的数据进行缓存?
- 是否只有当接收调用执行后才可以执行发送操作?
- 什么时候发送调用可以正确返回?
- 发送调用正确返回是否意味着发送完成?即发送缓冲区是否可以被覆盖?发送数据是否已到达接收缓冲区?
9.1标准通信模式
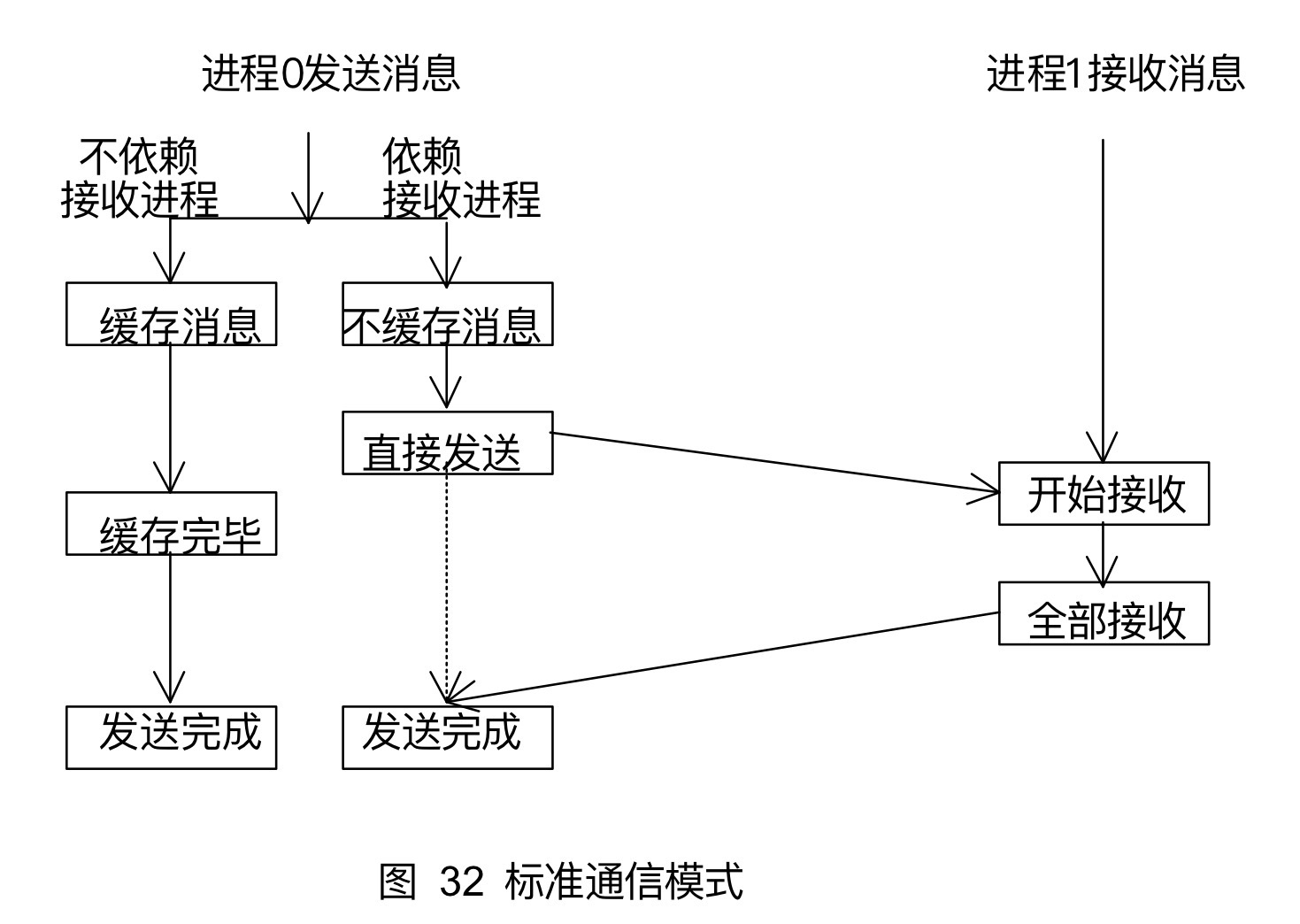
MPI采用标准通信模式,是否对发送的数据进行缓存是由MPI自身决定的,而不是由并行程序员来控制的。
9.2缓存通信模式
缓冲模式下,程序员可以自己对通信缓冲区申请、使用、释放。
xxxxxxxxxxMPI_BSEND(buf,count,datatype,dest,tag,comm)IN buf //发送缓冲区的起始地址IN count //发送数据的个数IN datatype//发送数据的数据类型IN dest //目标进程标识号IN tag //消息标志IN comm //通信域
int MPI_Bsend(void *buf,int count,MPI_Datatype datatype,int dest,int tag,MPI_Comm comm)
MPI_BSEND(BUF,COUNT,DATATYPE,DEST,TAG,COMM,IERROR)<type>BUF(*)INTEGER COUNT,DATATYPE,DEST,TAG,COMM,IERROR与MPI_Send不同仅在于通信时使用标准的系统提供的缓冲区,还是用户自己提供的缓冲区。
缓存通信模式不管接收操作是否启动,发送操作都可以执行,但是在发送消息之前必须有缓冲区可用,由用户保证。
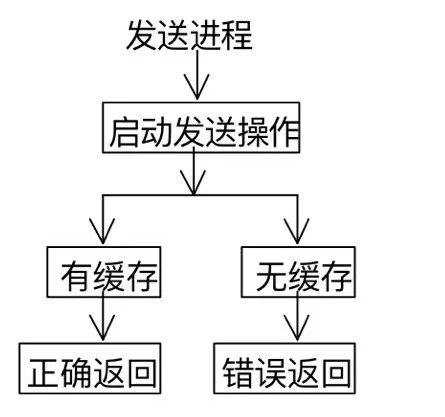
缓存通信模式,消息发送能否进行及能否正确返回不依赖于接收进程,完全依赖于是否有足够的通信缓冲区可用。
用户首先申请缓冲区,然后把它提交给MPI作为发送缓冲,用于支持发送进程的缓存通信模式。这样当缓存通信方式发生的时,MPI就可以使用这些缓冲区对消息进行缓存。当不适用这些缓冲区时,可以将缓冲区释放。
xxxxxxxxxxMPI_BUFFER_ATTACH(buffer,size)IN buffer //初始缓存地址IN size //按字节计数的缓存跨度(整型)
int MPI_Buffer_attach(void* buffer)
MPI_BUFFERR(*)<type>BUFFERR(*)INTEGER SIZE,IERROR
MPI_BUFFER_ATTACH将大小为size的缓冲区递交给MPI,这样该缓冲区就可以作为缓存发送时的缓存来使用。
xxxxxxxxxxMPI_BUFF_DETACH(buffer,size)OUT buffer //缓冲区初始地址OUT size //以字节为单位的缓冲区大小(整型)
int MPI_Buffer_detach(void** buffer,int *size)
MPI_BUFFER_DETACH(BUFFER,SIZE,IERROR)<type>BUFFER(*)INTEGER SIZE,IERRORMPI_BUFFER_DETACH将提交的大小为size的缓冲区buffer收回。该调用是阻塞调用,它一直等到使用该缓存的消息发送完成后才返回,这一调用后用户可以重新使用该缓冲区或者将这一缓冲区释放。
9.3同步通信模式
xxxxxxxxxxMPI_SSEND(buf,count,datatype,dest,tag,comm)IN buf //发送缓冲区的初始地址IN count //发送数据个数IN datatype //发送数据的数据类型IN dest //目标进程号IN tag //消息标识IN comm //通信域
int MPI_Ssend(void *buf,int count,MPI_Datatype datatype,int dest,int tag,MPI_Comm comm)
MPI_SSEND(BUF,COUNT,DATATYPE,DEST,TAG,COMM,IERROR)<type>BUF(*)INTEGER COUNT,DATATYPE,DEST,TAG,COMM,IERROR
同步通信模式的开始不依赖于接收进程相应的接收操作是否启动,但是同步发送却必须等到相应的接收进程开始后才可以正确返回。因此,同步发送返回后,意味着发送缓冲区中的数据已经全部被系统缓冲区缓存,并且已经开始发送。这样当同步发送返回后,发送缓冲区可以被释放和重新使用。
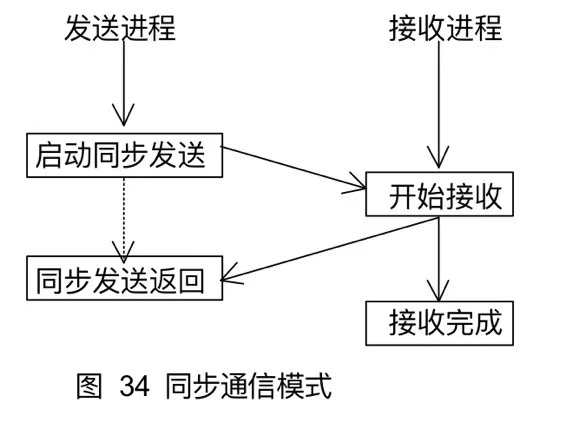
见vscode例子
9.4就绪通信模式
xxxxxxxxxxMPI_RSEND(buf,count,datatype,dest,tag,comm)IN buf //发送缓冲区的初始地址IN countIN datatypeIN destIN tagIN comm
int MPI_Rsend(void*buf,int count,MPI_Datatype datatype,int dest,int tag,MPI_Comm comm)
MPI_RSEND(BUF,COUNT,DATATYPE,DEST,TAG,COMM,IERROR)<type>BUF(*)INTEGER COUNT,DATATYPE,DEST,TAG,COMM,IERROR就绪通信模式,只有接收进程的接收操作已经启动时,才可以在发送进程启动发送操作,否则,当发送操作启动而相应的接收还没有启动时,发送操作将出错。
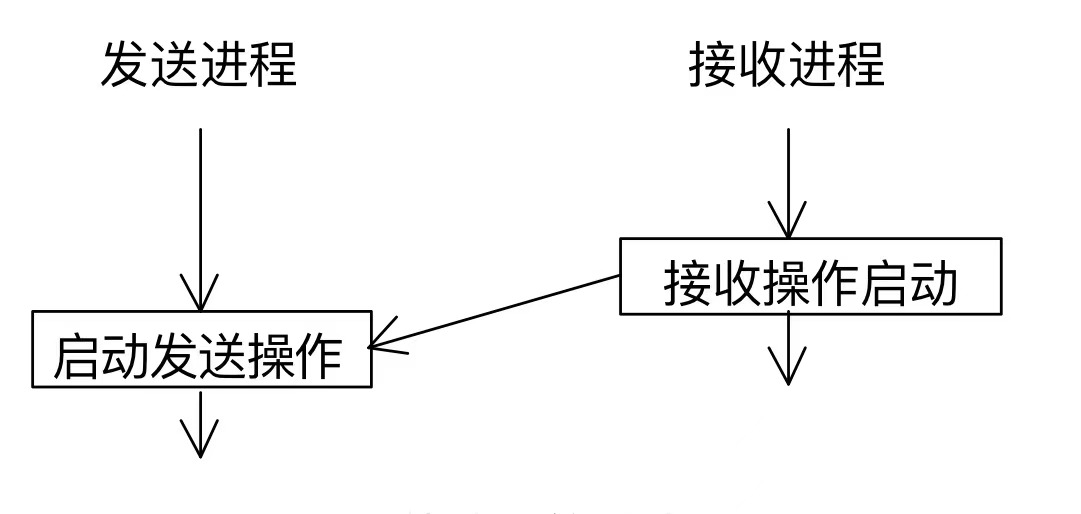
就绪模式要求接收操作先于发送操作而被启动,对于语义没有影响而对于性能有影响。
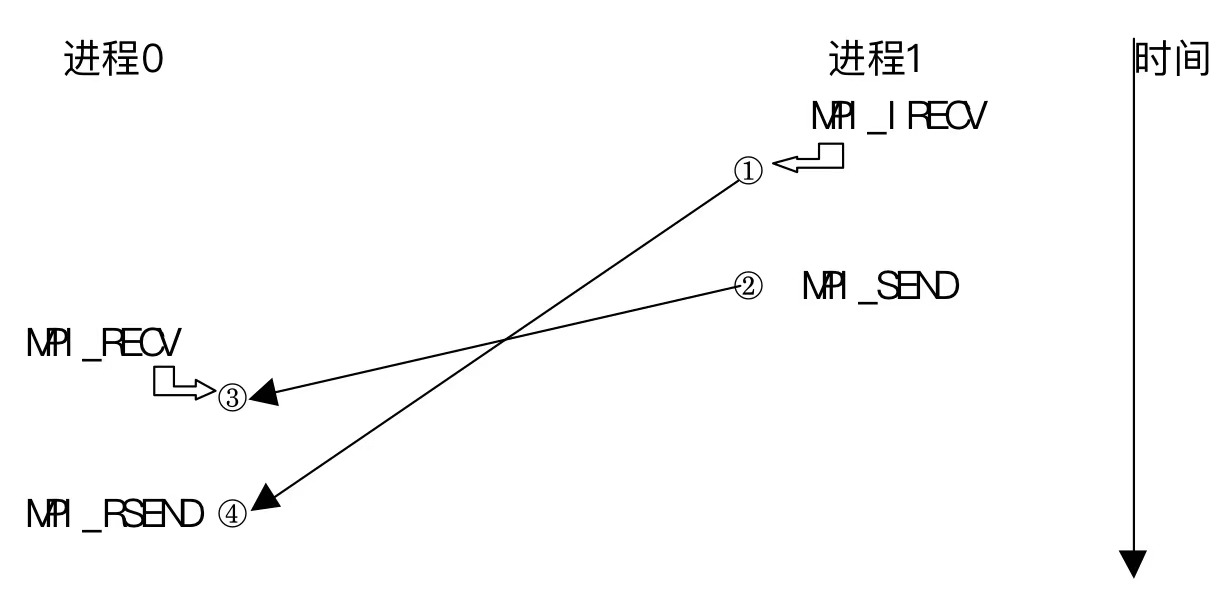
①MPI_IRECV 调用返回的时刻
②开始执行MPI_SEND的时刻
③MPI_RECV完成时刻
④开始执行MPI_RSEND的时刻
例子见vscode
9.5总结
四种标准通信模式的区别
高性能计算--mpi(二) - 知乎 (zhihu.com)
第十章 MPICH的安装与MPI程序的运行
略
第十一章
略
第十二章 非阻塞通信MPI程序设计
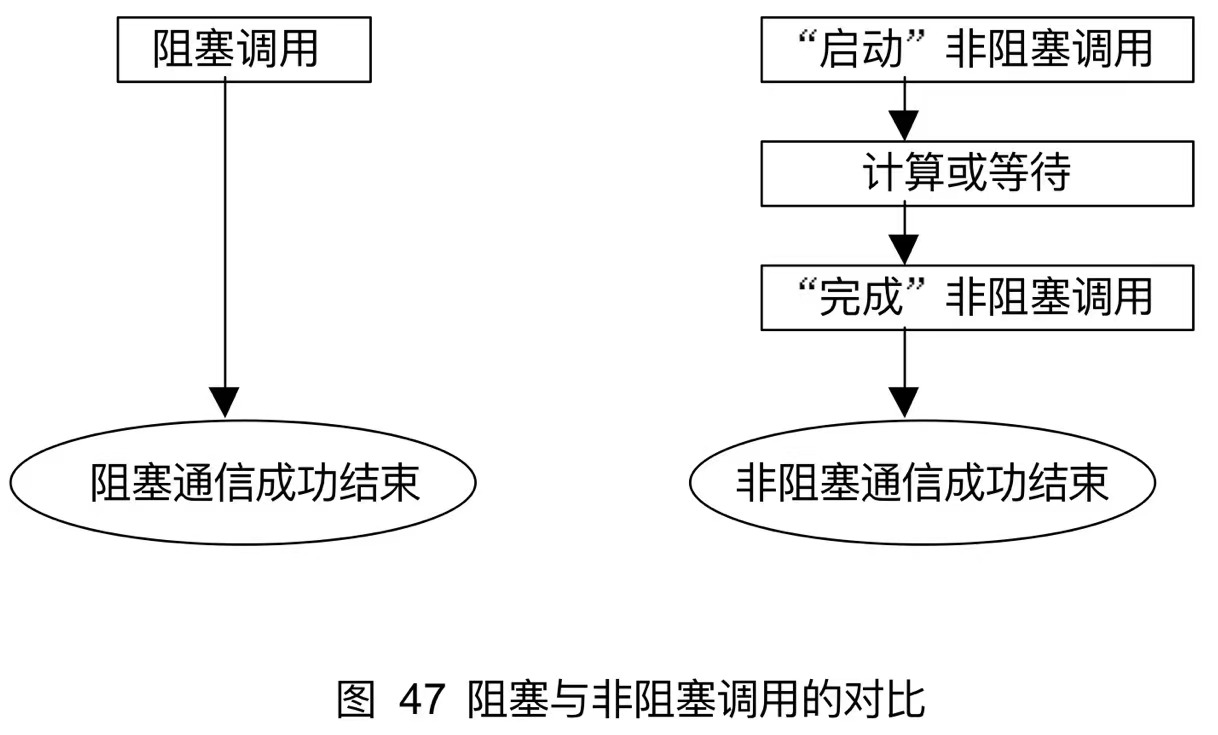
非阻塞通信主要用于实现计算与通信的重叠
12.1 阻塞通信
当一个阻塞通信正确返回后
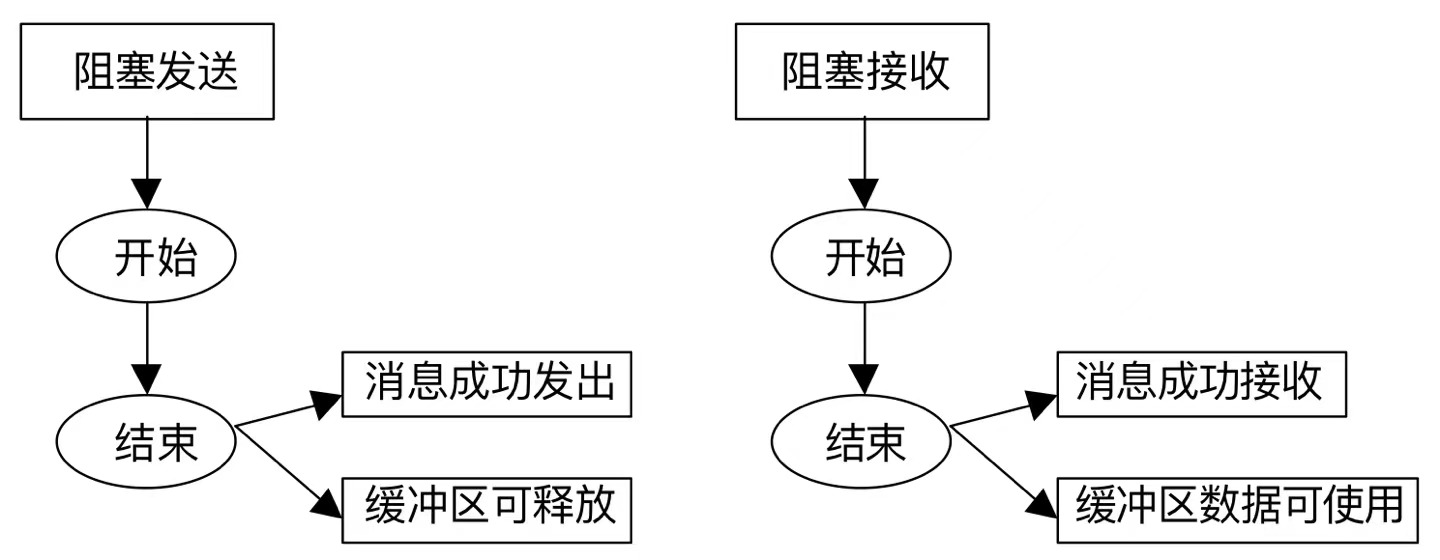
阻塞发送必须遵守 有序接收的语义约束
如果进程0发送的第二条消息到了,也不能接收,只有第一条消息到后了,并接收完才能接收第二条消息
12.2非阻塞通信介绍
非阻塞通信的目的主要用于计算和通信的重叠,,可以大大提高程序执行的效率。
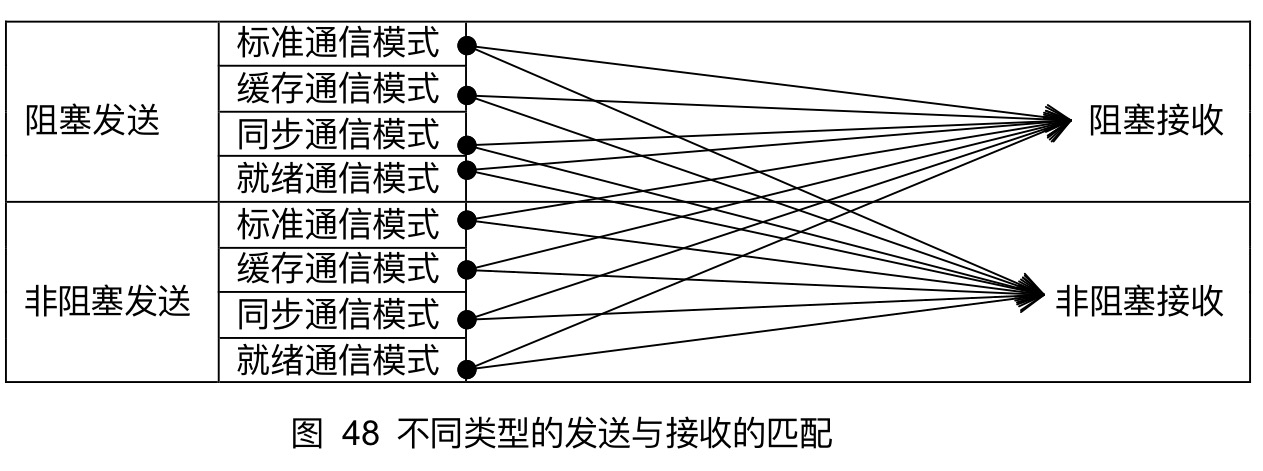
只要消息信封相吻合,并且有序接收的语序约束,
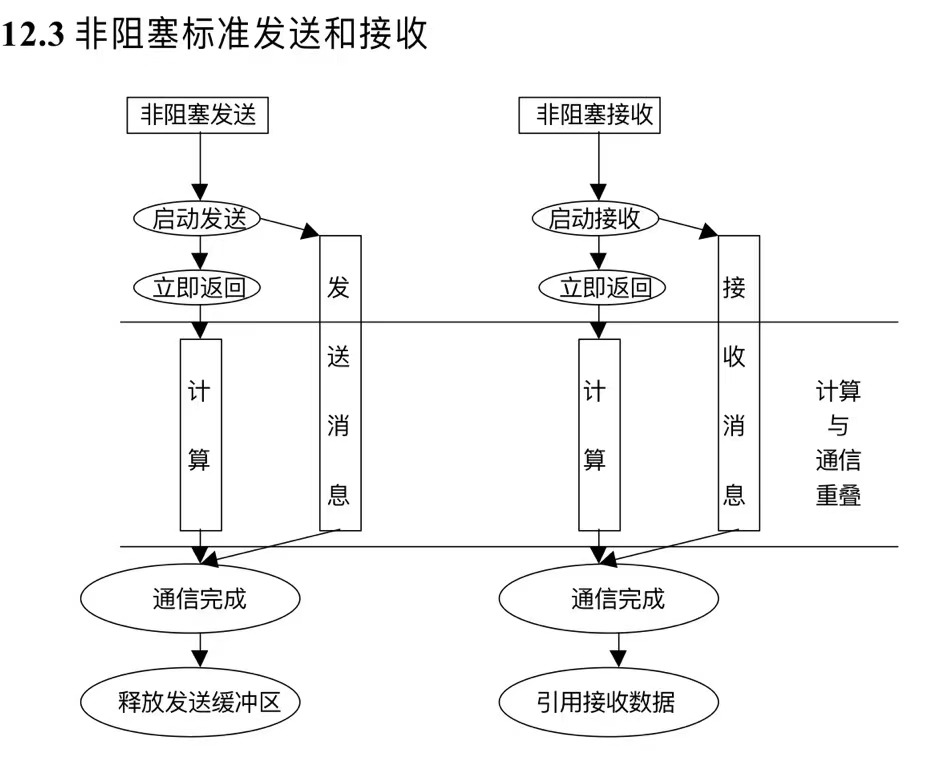
函数:
xxxxxxxxxxMPI_Isend(void* buf,int count,MPI_Datatype datatype, int dest,int tag,MPI_Comm comm, MPI_Request* request) MPI_Irecv(void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Request* request)这里比阻塞通信多了一个request项,request项用来查询对应的非阻塞接收是否完成
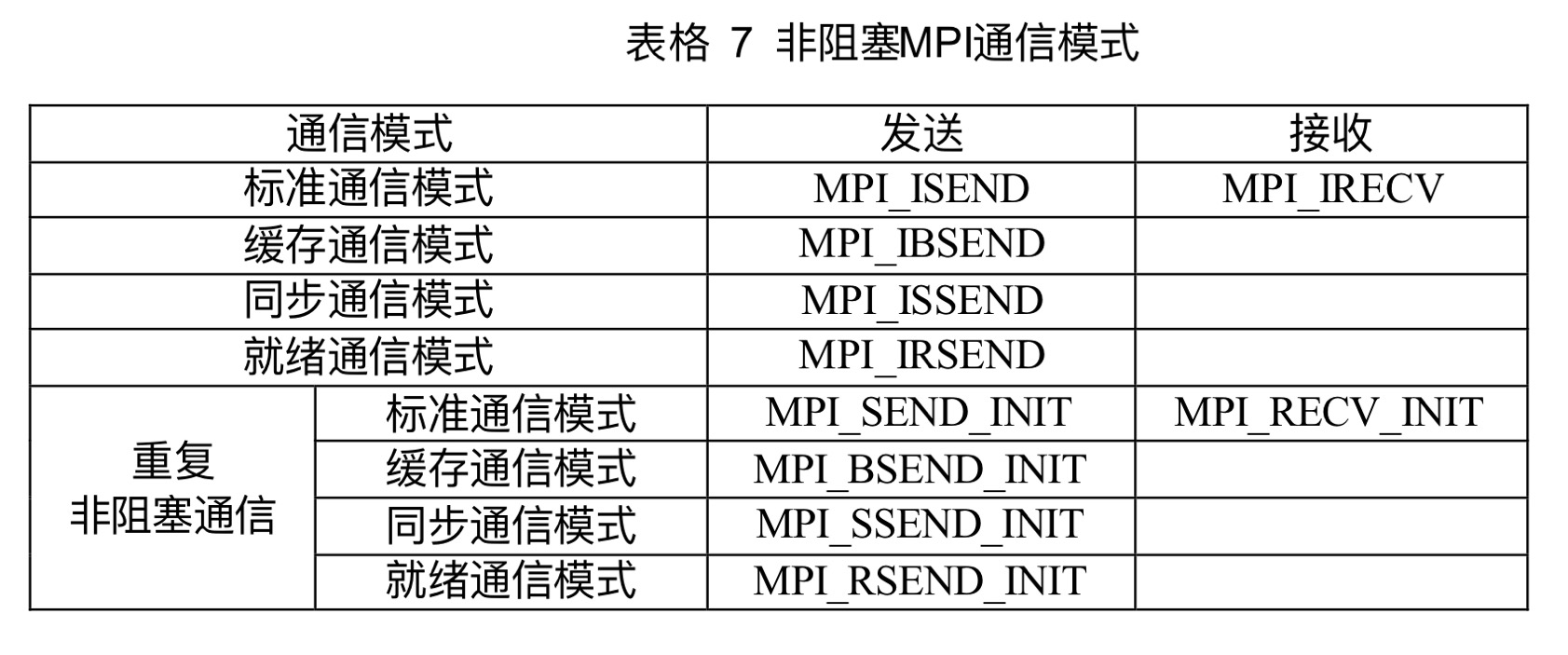
12.4非阻塞通信与其他三种通信模式的组合
xxxxxxxxxxMPI_Issend() //同步模式MPI_Ibsend() //缓存模式MPI_Irsend() //接收就绪模式,要求调用前接收操作已启动
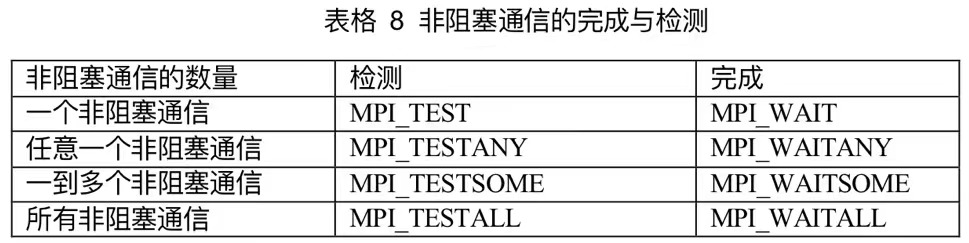
12.5非阻塞通信的完成
对于单个的非阻塞通信的完成
xxxxxxxxxxint MPI_Wait(MPI_Request *request, MPI_Status *status)
int MPI_Test(MPI_Request *request, int *flag, MPI_Status *status)二者都可以检验非阻塞过程是否完成但是有差异
MPI_Wait
检测时如果完成则返回True,否则一直等到非阻塞过程正确返回
MPI_Test
检测时如果完成则返回True,否则返回False,不会等待
对于多个的非阻塞通信的完成
xxxxxxxxxxint MPI_Watiany(int count, //非阻塞通信对象的个数MPI_Request *array_of_requests, //非阻塞通信完成对象数组int *index, //完成对象对应的句柄索引MPI_Status *status //返回状态)等待非阻塞通信表中任何一个非阻塞通信对象的完成,释放已完成的非阻塞通信对象
xxxxxxxxxxint MPI_Waitall(int count, //非阻塞通信个数 MPI_Request *array_of_request, //非阻塞通信完成对象数组MPI_Status *array_of_status //状态数组)必须等到非阻塞通信对象表中所有的非阻塞通信对象相应的非阻塞操作都完成后,才返回
xxxxxxxxxxint MPI_Waitsome(int incount, //非阻塞通信对象个数MPI_Request *arrary_of_request, //非阻塞通信对象数组int *outcount, //已完成对象的数目int *arrary_of_indices, //已完成对象的下标数组MPI_Status *arrary_of_statuses //已完成对象的状态数组)只要有一个或多个非阻塞通信完成,则该调用返回,完成对象的个数记录在outcount中,相应的对象在arrary_of_requests中的下标记录在数组arrary_of_indices中,状态记录在状态数组中。
类似
MPI_Testany用于测试通信对象列表中是否有任何一个对象已经完成(多个对象完成时,任选一个),若有则零flag=true,释放该对象后返回,若没有,则flag=false返回
MPI_Testall只有当所有非阻塞通信对象都完成时,才使得flag=true返回,并释放所有查询对象,只要有一个没有完成则令flag=false
MPI_Testsome有几个完成则outcount等于几,完成对象在arrary_of_indices中下标记录,若没有完成的,则返回值outcount=0
12.6.1非阻塞通信的取消
MPI_CANCEL允许取消已调用的非阻塞通信,取消命令释放发送或接收操作所占用的资源,该调用立即返回。
取消调用并不意味着相应的通信一定会被取消。
如果取消操作调用时,非阻塞通信已经开始,则他会正常完成,不受影响
如果还没有开始则会释放通信占用的资源
xxxxxxxxxxint MPI_Cancel(MPI_Request *request)如果一个非阻塞通信已经被取消,则该通信的MPI_WAIT或者MPI_TEST将释放取消通信的非阻塞通信对象,并在返回结果status中指明该通信已经被取消。
一个通信操作是否被取消,可以通过调用测试函数来检查
xxxxxxxxxxint MPI_Test_cancelled(MPI_Status status, int *flag)
12.6.2非阻塞通信对象的释放
当程序猿能确认一个非阻塞通信操作完成时,可以直接调用非阻塞通信对象释放语句,将该对象所占用的资源释放
xxxxxxxxxxint MPI_Request_free(MPI_Request *request)
12.7消息到达检查
xxxxxxxxxxint MPI_Iprobe(int source, int tag, MPI_Comm comm,int *flag, MPI_Status *status)该函数被调用时,如果存在一个消息可被接受,并且该消息信封和MPI_Iprobe的消息信封匹配则返回flag=true,返回状态同MPI_Recv函数中的status;如果没有消息到达或到达消息信封不匹配则返回false
source 和 tag 参数可以填入ANY_SOURCE 和 ANY_TAG
xxxxxxxxxxint MPI_Probe(int source, int tag, MPI_Comm comm, MPI_Status *status)同上不过该调用是一个阻塞调用,只有找到一个匹配的消息到达之后它才会返回。
12.8非阻塞通信又须接受的语义约束
对于非阻塞通信来说,和阻塞通信一样,也有有序接收的语义约束,进程A向进程B发送的消息只能被进程B第一个匹配语句接收。
12.10重复非阻塞通信
如果一个通信会被重复执行,例如循环中的通信调用,MPI提供了特殊的实现方式,对这样的通信进行优化,以降低不必要的开销
操作如下:
xxxxxxxxxxMPI_SEND_INIT //通信初始化MPI_START //启动通信MPI_WAIT //完成通信MPI_REQUEST_FREE //释放查询对象
xxxxxxxxxxint MPI_Send_init(void *buf, int count, MPI_Data type, int dest, int tag, MPI_Comm comm, MPI_Request *request)
xxxxxxxxxxint MPI_Start(MPI_Request *request)
int MPI_Startall(int count, MPI_Request *arrary_of_request) //启动表中每一个非阻塞通信通信缓冲区从该调用开始禁止访问,直到操作完成
第十三章 组通信MPI程序设计
MPI组通信和点到点通信的一个重要区别在于它需要一个特定组内的所有进程同时参加通信,而不是象点到点通信那样在形式上有发送和接收的区别。
13.1组通信概述
组通信的调用可以和点对点通信共用一个通信域,由MPI保证组通信调用产生的消息不会和点对点调用产生的消息混淆,组通信中不需要通信消息标志参数
组通信一般实现三个功能:通信、同步和计算。
通信功能主要完成组内数据的传输,而同步功能实现组内所有进程在特定的地点在执行进度上取得一致,计算功能要对给定的数据完成一定的操作。
13.1.1 组通信的消息通信功能
对于组通信,可以分为以下三种:
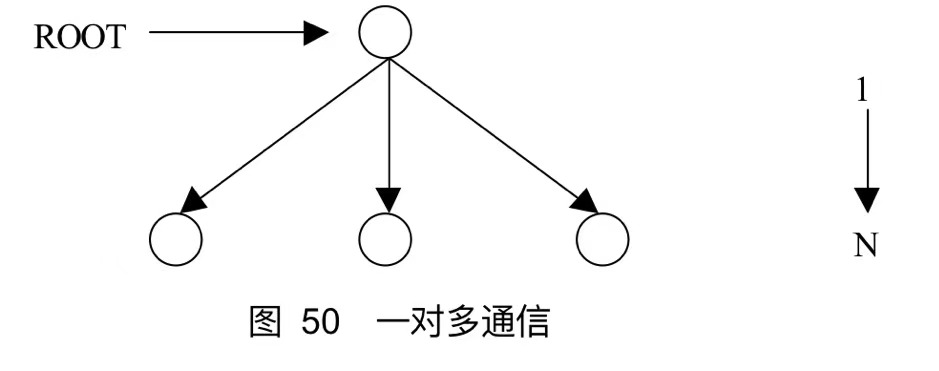
一个进程向其他所有进程发送消息,广播是最常见的一对多通信例子
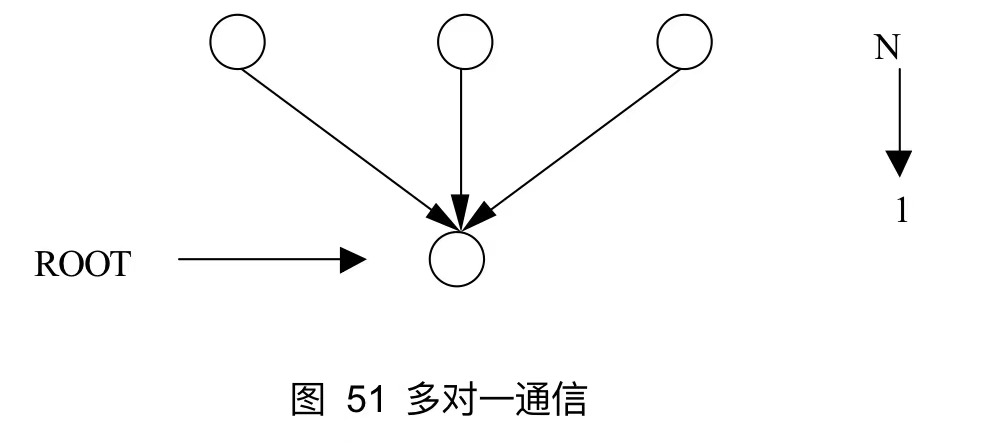
多对一通信,一个进程从其他所有进程接收消息,收集是最常见的多对一通信的例子
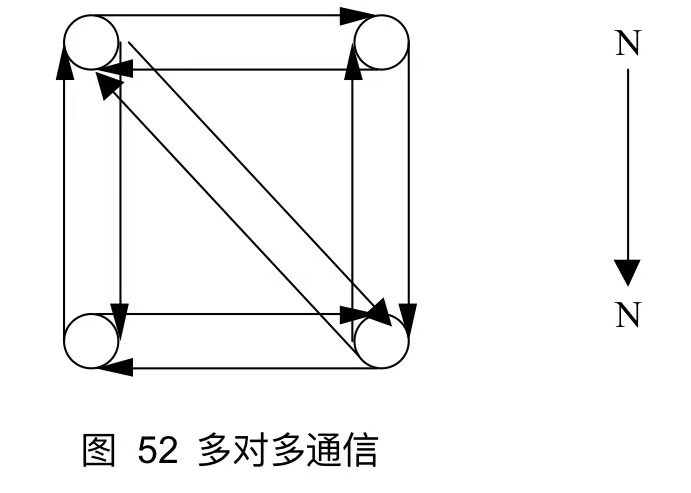
每个进程都向其他进程发送消息,或者每一个进程都从其他所有进程接收消息
一个进程完成了它自身的组通信调用后,就可以释放数据缓冲区或使用缓冲区中的数据,但是不代表一个进程组通信都完成了。
13.1.2 组通信的同步功能
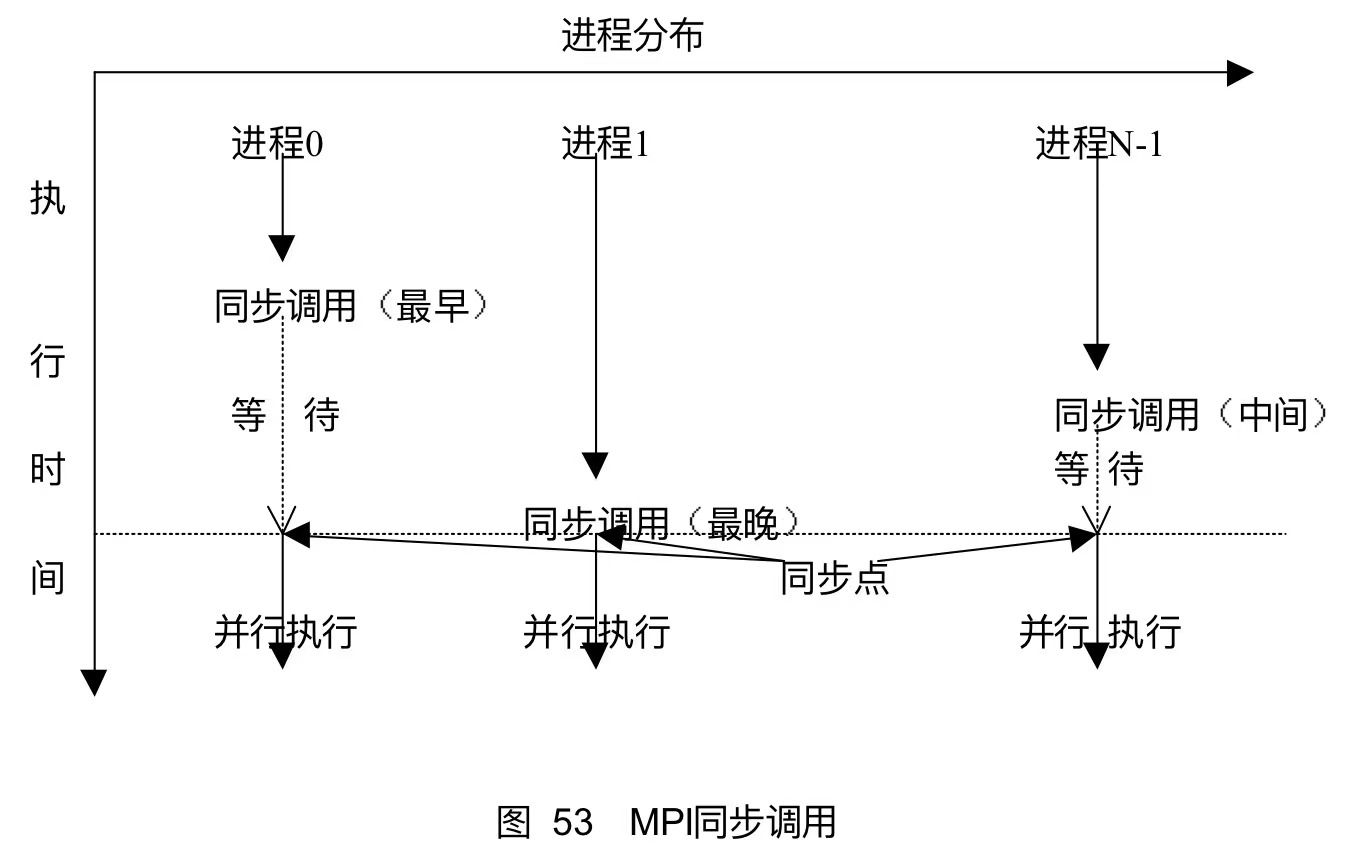
不同进程执行的进度不同,本例中进程0首先执行到同步调用,执行同步操作,但是,由于其他进程还没有到达同步调用点,因此进程0只好等待,其他进程陆续到达同步调用点,只要有一个进程未达到同步调用点,其他进程都必须等待
13.1.3 组通信的计算功能
对消息的处理,即计算部分,用给定的计算操作对接收到的数据进行处理
13.2广播
xxxxxxxxxxint MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm)都使用同一个通信域comm和根标识root,执行结果是将根进程通信消息缓冲区中的消息拷贝到其他所有进程中去。
13.3收集
典型多对一的例子,每个进程将其发送缓冲区中的消息发送到跟进程,根进程根据发送进程的进程标识的序列号即进程rank,将他们各自的消息依次放到自己的消息缓冲区中。
收集调用每个进程发送数据个数sendcount和发送数据类型sendtype都是相同的
根进程中指定的接收数据个数是指从每一个进程接收到的数据的个数,而不是总接收个数
对于所有非根进程,接收消息缓冲区被忽略,但是各个进程必须提供这一参数
xxxxxxxxxxint MPI_Gather(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, Datatype recvtype, int root, MPI_Comm comm)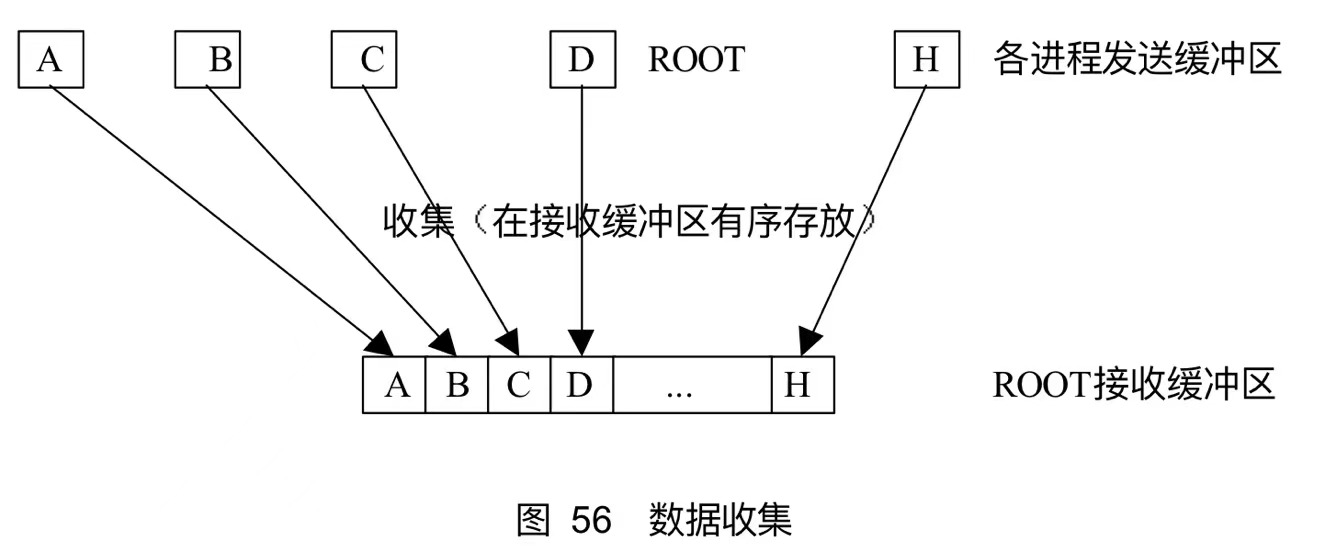
MPI_Gatherv也是类似的功能,但是不同的是它可以从不同的进程接收不同数量的数据,它的参数中recvcount是一个数组,并且还提供一个位置偏移displs数组,用户可以将接收的数据存放到根进程消息缓冲区的任意位置,相比MPI_Gather灵活也更复杂
xxxxxxxxxxint MPI_Gatherv(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int *recvcount, int *displs, MPI_Datatype recvtype, int root, MPI_Comm comm)
13.4散发
散发是一对多的组通信调用,但是和广播不同,root向各个进程发送的数据可以是不同的
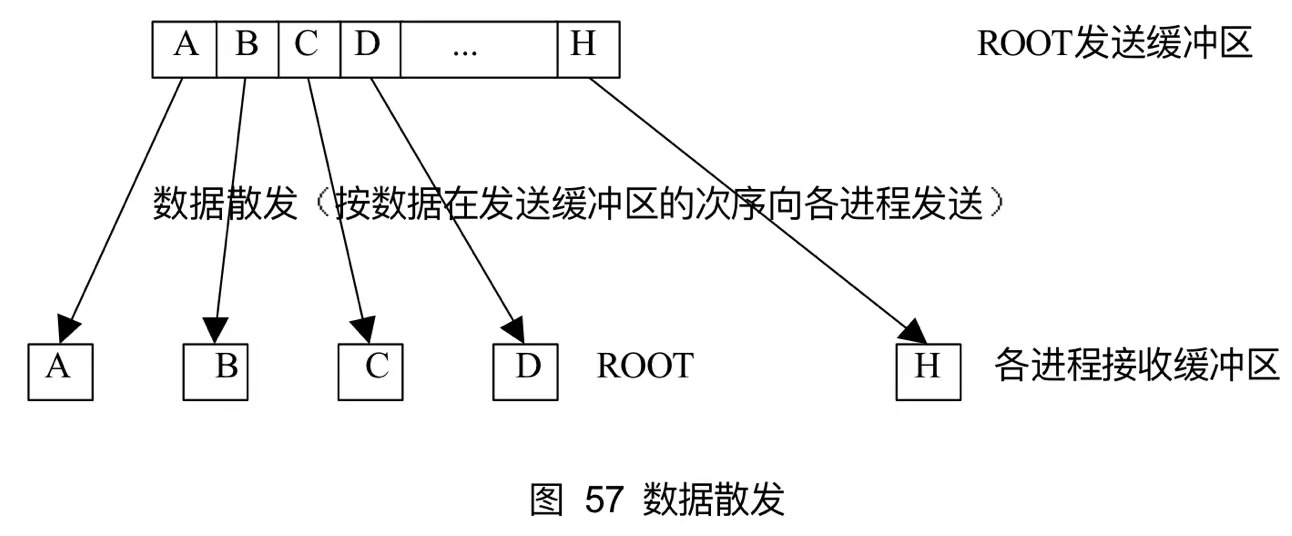
xxxxxxxxxxint MPI_Scatter(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm)
同样
MPI_Scatter也有更灵活的版本,允许发送不同数据量,存放在指定位置的版本MPI_Scatterv
xxxxxxxxxxint MPI_Scatterv(void *sendbuf, int *sendcounts, int *displs, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm)
13.5组收集
组收集相当于每一个进程都作为root执行了依次MPI_Gather调用,即每一个进程都收集到了其它所有进程的数据
xxxxxxxxxxint MPI_Allgather(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, MPI_Comm comm)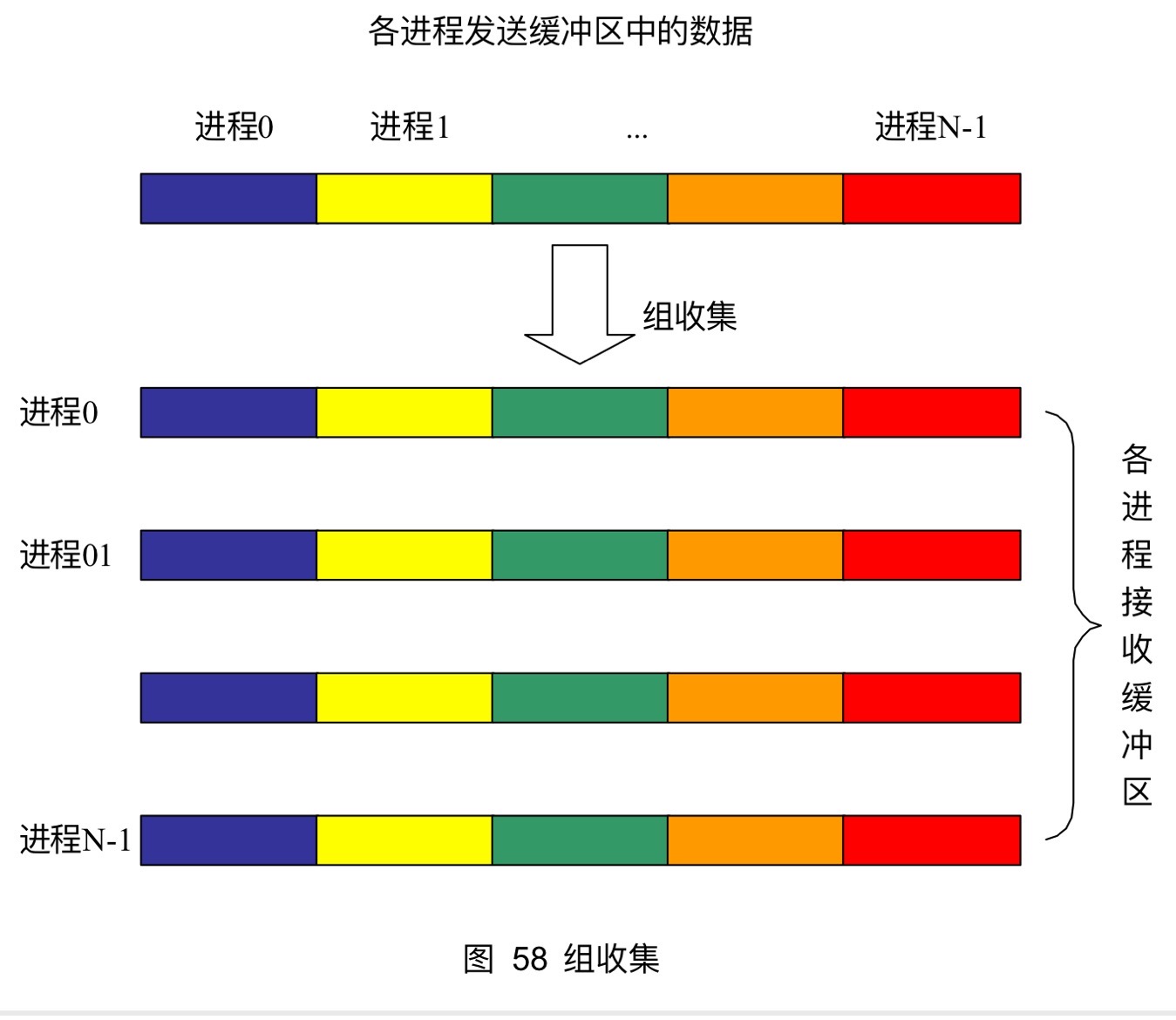
同样与之对应的还有
MPI_ALLGATHERV能指定存放的指针偏移量
xxxxxxxxxxint MPI_Allgatherv(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int *recvcounts, int*displs, MPI_Datatype recvtype, MPI_Comm comm)
13.6全互换
组内进程之间完全的消息互换,每一个进程都向其他所有进程发送消息,同时每一个进程都从其他所有的进程接收消息。
xxxxxxxxxxint MPI_Alltoall(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, MPI_Comm comm)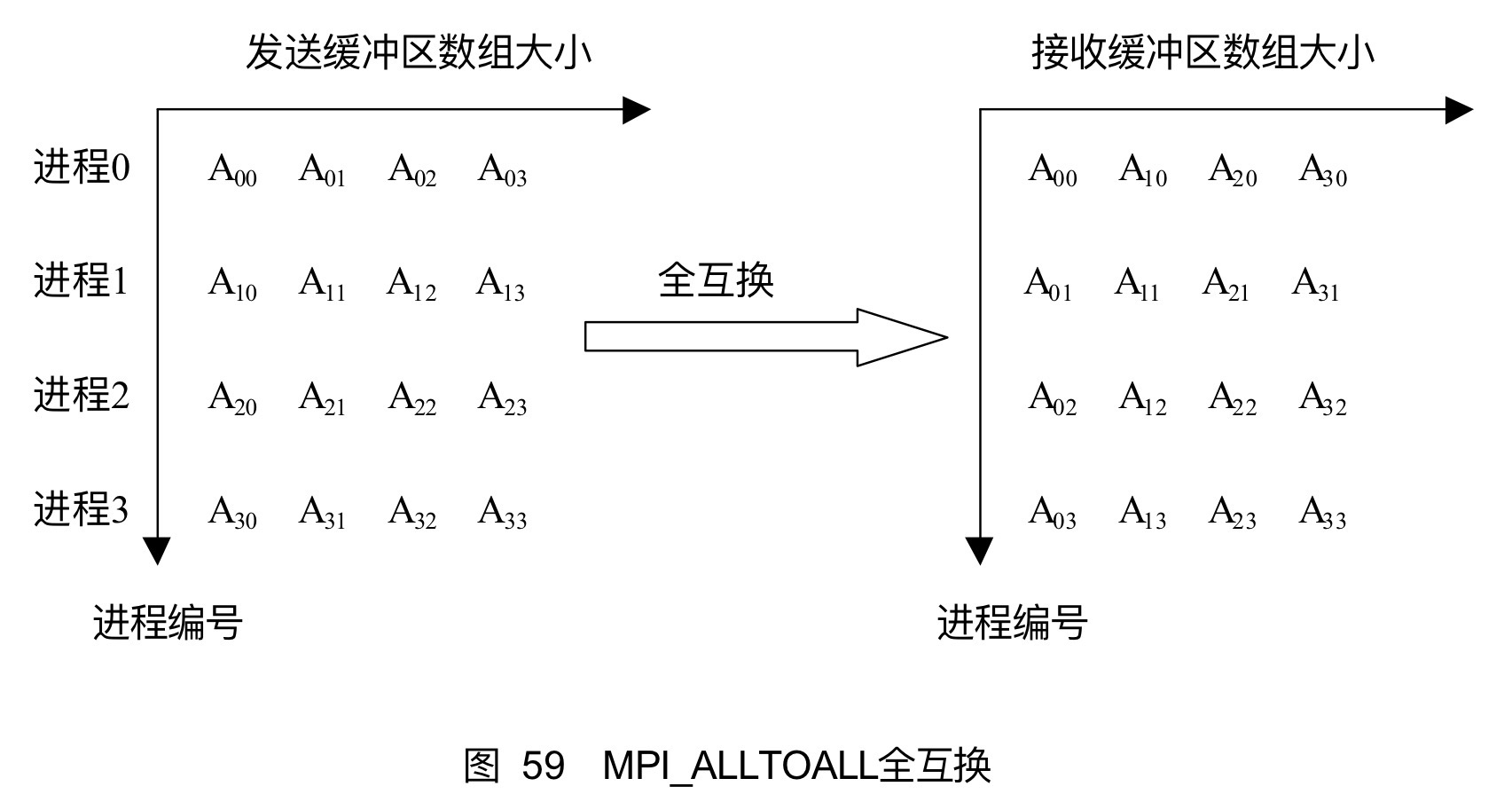
交换后是之前的转置
13.7同步
xxxxxxxxxxint MPI_Barrier(MPI_Comm comm)阻塞所有调用者直到所有的组成员都调用了它
13.8规约
将组内每个进程输入缓冲区中的数据按给定的操作op进行运算,并将其结果返回到序列号为root的进程的输出缓冲区中。
xxxxxxxxxxint MPI_Reduce(void *sendbuf, void *recvbuf, int count, PI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm)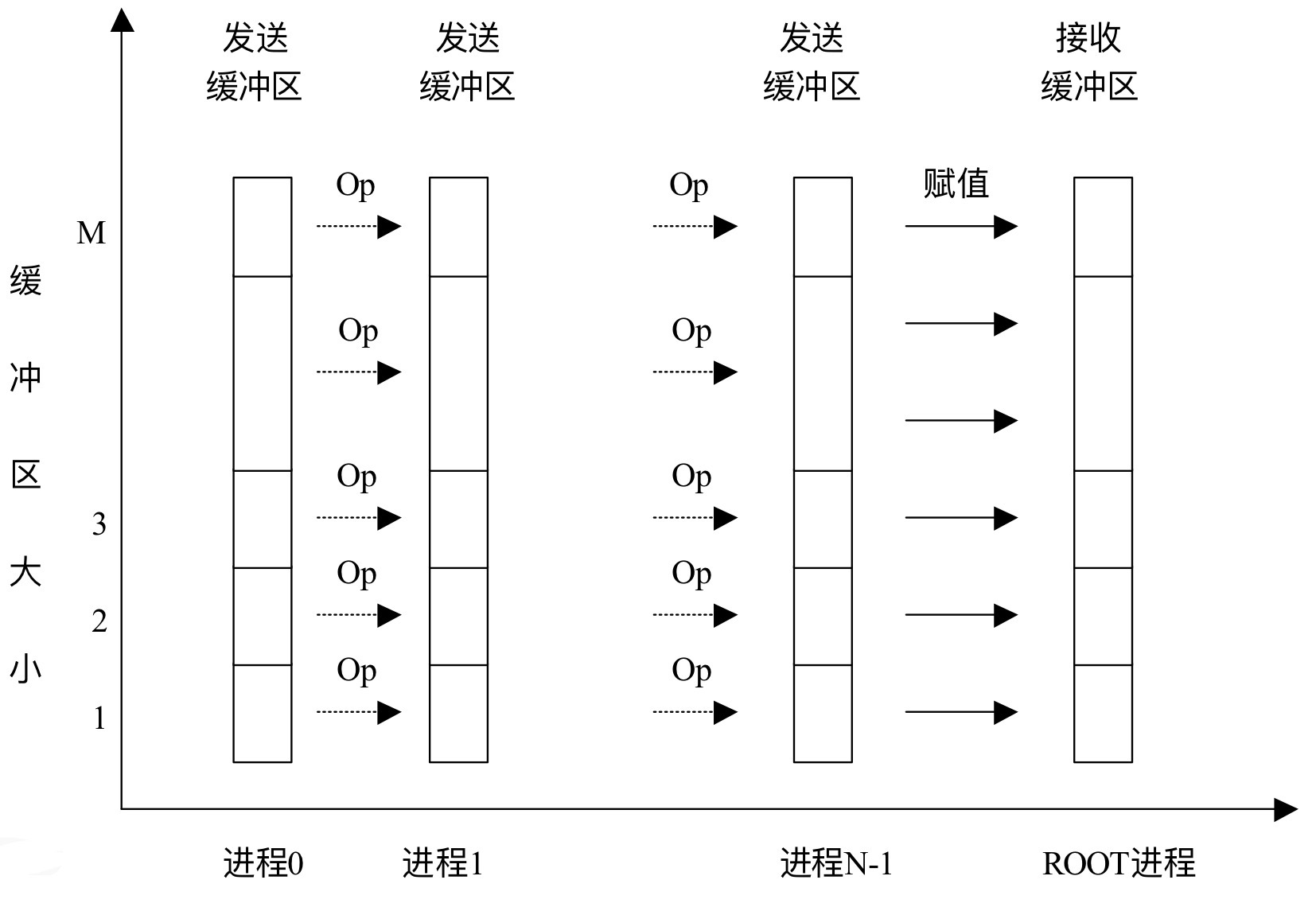
MPI预定义的规约操作
| 名字 | 含义 |
|---|---|
| MPI_MAX | 最大值 |
| MPI_MIN | 最小值 |
| MPI_SUM | 求和 |
| MPI_PROD | 求积 |
| MPI_LAND | 逻辑与 |
| MPI_BAND | 按位与 |
| MPI_LOR | 逻辑或 |
| MPI_BOR | 按位或 |
| MPI_LXOR | 逻辑异或 |
| MPI_BXOR | 按位异或 |
| MPI_MAXLOC | 最大值且相应位置 |
| MPI_MINLOC | 最小值且相应位置 |
13.11组规约
组中每一个进程都作为root分别进行了一次规约操作
xxxxxxxxxxint MPI_Allreduce(void *sendbuf, void *recvbuf, int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
13.13扫描
扫描是一种特殊的规约,每一个进程都对排在它前面的进程进行规约操作
xxxxxxxxxxint MPI_Scan(void *sendbuf, void *recvbuf, int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
第十四章 具有不连续数据发送的MPI程序设计
MPI还可以处理不连续的数据,基本方法有两种,一种是允许用户自定义的数据类型,二是数据的打包与解包,即在发送方将不连续的数据打包到连续的区域,然后发送出去,在接受方将打包后的连续数据解包到不连续的存储空间
14.2 新数据类型的定义
14.2.1 连续复制的类型生成
最简单的数据类型生成器是MPI_TYPE_CONTIGUOUS,他得到的新类型是将一个已有的数据类型按顺序依次连续进行复制后的结果。
xxxxxxxxxxint MPI_Type_contiguous(int count, MPI_Dataype oldtype, MPI_Datatype *newtype)设原来的数据类型oldtype的类型图为{(double,0)(char,8)},其中类型的跨度为extent=16,对旧类型重复的次数count=3,则newtype返回的新类型的类型图为{(double,0),(char,8),(double,16),(char,24),(double,32),(char,40)}
14.2.2 向量数据类型的生成
MPI_TYPE_VECTOR是一个更通用的生成器,允许复制一个数据类型到含有想等大小块的空间。每个块通过连接相同数量的旧数据类型的拷贝来获得。块与块之间的空间是旧数据类型的extent的倍数
xxxxxxxxxxint MPI_Type_vector( int count, //块的数量 int blocklength, //每个块中所含元素个数 int stride, //各块第一个元素之间相隔的元素个数 MPI_Datatype oldtype, //旧数据类型 MPI_Datatype *newtype //新数据类型)
14.2.3 索引数据类型的生成
复制一个旧数据类型到一个块序列中(每个块是就数据类型的一个连接)
没看懂,略,看到这里麻烦提醒我补起来这块内容,联系邮箱3097847063@qq.com
第十五章 MPI的进程组和通信域
通信域包括通信上下文,进程组,虚拟处理器拓展,属性等内容,用于综合描述了通信进程间的通信关系。
通信域分为组内通信和组间通信域。
组内通信域用于描述属于同一组内进程的通信
组间通信域用于描述属于不同进程组的进程间的通信
MPI_GROUP_EMPTY是一个特殊的预定义组,他没有成员。预定义的常数MPI+GROUP_NULL是为无效组句柄使用的值。因此不应将MPI_GROUP_NULL与MPI_GROUP_EMPTY弄混,后者是一个空组的有效句柄,而前者则是一个无效句柄。后者可以在组操作中作为一个参数使用,前者在组释放时被返回
一旦
MPI_INIT被调用,则会产生一个预定义组内通信域MPI_COMM_WORLD,它包括所有的进程
15.2 进程组的管理
xxxxxxxxxxint MPI_Group_size(MPI_Group group,int *size)返回指定进程组中所包含的进程的个数
xxxxxxxxxxint MPI_Group_rank(MPI_Group group, int *rank)返回调用进程在给定进程组中的编号rank,类似于MPI_COMM_RANK,如果调用进程不在给的那个的进程组内,则返回MPI_UNDEFINED
xxxxxxxxxxint MPI_Group_translate_ranks(MPI_Group group1, int n, int *ranks1, MPI_Group group2, int *ranks2)返回进程组group1中的n个进程在进程组group2中对应的编号,若不包含进程组1中指定的进程则返回
MPI_UNDEFINED。此函数可以检测两个不同进程组中相同的进程的对应编号。例如知道了在组MPI_COMM_WORLD中某些进程的序列号,也想知道在该组的子集中它们的序列号。
xxxxxxxxxxint MPI_Group_compare(MPI_Group group1, MPI_Group group2, int *result)对两个进程组进行比较:
如果两个进程组包含的进程以及相同进程的编号都完全一样则返回
MPI_IDENT如果包含进程完全相同但是相同进程的编号不一样则返回
MPI_SIMILAR否则返回
MPI_UNEQUAL
xxxxxxxxxxint MPI_Comm_group(MPI_Comm comm, MPI_Group *group)返回指定通信域所包含的进程组
xxxxxxxxxxint MPI_Group_union(MPI_Group group1, MPI_Group group2, MPI_Group *newgroup)返回新进程组是group1中所有进程加上group2中不在group1中出现的进程
xxxxxxxxxxint MPI_Group_intersection(MPI_Group group1, MPI_Group group2, MPI_Group *newgroup)新进程组包含同时在group1以及group2中出现的所有进程
xxxxxxxxxxint MPI_Group_difference(MPI_Group group1, MPI_Group group2, MPI_Group *newgroup)返回新进程组包含在group1中却又不在group2中的进程
xxxxxxxxxxint MPI_Group_incl(MPI_Group group, int n, int *ranks, MPI_Group *newgroup)将已有进程组中的n个进程rank[0], ..., rank[n-1]形成一个新group,此函数可用于对于进程组中元素重排
xxxxxxxxxxint MPI_Group_excl(MPI_Group group, int n, int *rank, MPI_Group *newgroup)将进程组中n个进程rank[0], ..., rank[n-1]删除后形成新的进程组
xxxxxxxxxxint MPI_Group_range_incl(MPI_Group group, int n, int range[][3], //三元组整数数组 (first,last,stride) MPI_Group *newgroup)将已有进程组group中的n组由range指定的进程形成一个新的进程组newgroup
xxxxxxxxxxint MPI_Group_range_excl(MPI_Group group, int n, int range[][3], MPI_Group *newgroup)从已有进程组中删除n个三元组rangs所指定的进程后形成新的newgroup
xxxxxxxxxxitn MPI_Group_free(MPI_Group *group)释放
15.3 通信域的管理
xxxxxxxxxxint MPI_Comm_size(MPI_Comm comm, int *size)返回给定的通信域中包含的进程的个数
xxxxxxxxxxint MPI_Comm_rank(MPI_Comm comm, int *rank)返回给定通信域中进程编号
xxxxxxxxxxint MPI_Comm_compare(MPI_Comm comm1, MPI_Comm comm2, int *result)对两个给定的通信域进行比较:
当comm1和comm2同一对象句柄时,结果为
MPI_IDENT当仅仅是各进程组队成员和序列号都相同,则结果为
MPI_CONGRUENT如果组成员相同,序列号不同则返回
MPI_SIMLAR否则返回
MPI_UNEQAL
xxxxxxxxxxint MPI_Comm_dup(MPI_Comm comm, MPI_Comm *newcomm)对已有的通信域comm进行复制,得到一个新的通信域newcomm
xxxxxxxxxxint MPI_Comm_create(MPI_COMM comm, MPI_Group group, MPI_Comm *newcomm)根据group所定义的进程组,创建一个新的通信域,该通信域具有新的上下文
xxxxxxxxxxint MPI_Comm_split(MPI_Comm comm, int color, int key, MPI_Comm *newcomm)每一个进程都要指定一个color值根据该值将具有相同color值的进程形成一个新的进程组,新产生的通信域与这些进程组一一对应,新通信域中各进程的顺序编号根据key的大小决定的
xxxxxxxxxxint MPI_Comm_free(MPI_Comm *comm)释放给定通信域
15.4 组间通信
组间通信是一种特殊的通信域,该通信域包含两个进程组,通过组间通信域实现这两个不同进程组内进程之间的通信。一般把调用进程所在的进程组叫做本地组,而把另一个组叫做远程组
xxxxxxxxxxint MPI_Comm_test_inter(MPI_Comm comm, int *flag)判断给定的通信域是组内通信域还是组间通信域,如果是组间通信域返回true,否则返回false
xxxxxxxxxxint MPI_COMM_Comm_remote_size(MPI_Comm comm, int *size)返回组间通信域内远程进程组的进程个数
xxxxxxxxxxint MPI_COMM_Comm_remote_size(MPI_Comm comm, int *size)返回组间通信域内远程进程组的进程个数
xxxxxxxxxxint MPI_Comm_remote_group(MPI_Comm comm, MPI_Group *group)返回组间通信域中的远程进程组
xxxxxxxxxxint MPI_Intercomm_create( MPI_Comm local_comm, //本地组内通信域 int local_leader, //本地组内特定进程的标识号 MPI_Comm peer_comm, //对等通信域,仅在local_leader中有意义 int remote_leader, //远程组特定进程在peer_comm中对应的标识号 int tag, //“安全”标志 MPI_Comm *newintercomm //返回的新组间通信域)创建一个组间通信域,包括两个通信域。
每个进程提供自身所在的一个通信域local_comm中特定进程的标识local_leader(同一个本地进程组中的进程给出的local_leader必须相同),同时给出另一个通信域中特定进程在peer_commzhong 的标识remote_leader形成相同
xxxxxxxxxxint MPI_Intercomm_merge(MPI_Comm *newintracomm, int high, MPI_Comm *newintracomm)将一个组间通信域的两个通信域合并成一个组内通信域,根据提供的hight值决定新形成的通信域中进程编号
15.5属性信息
xxxxxxxxxxint MPI_Keyval_creat(MPI_Copyfunction *copy_fn, //用于keyval的复制回调函数MPI_Delete_function *delete_fn, //用于keyval的删除回调函数int *keyval, //用于将来访问关键字的值void *extra_state //回调函数的外部状态)创建一个新的属性的关键字,根据返回的关键字,可以对特定的属性进行管理和操作。关键字在进程内时本地唯一的,而且对用户不透明,虽然它们显式地以整数方式存储,一旦被分配,关键字的值可以在任何本地定义的通信域上与属性建立联系并访问它们
xxxxxxxxxxint MPI_Keyval_free(int *keyval)释放一个现存的属性关键字,此函数将keyval的值置为
MPI_KEYVAL_INVALID。释放一个正在使用的属性关键字不会出错,因为实际释放发生在直到当前对次关键字的所有引用都释放时才进行。
xxxxxxxxxxint MPI_Attr_put(MPI_Comm comm, int keyval, void *attribute_val)设置指定关键字的属性值
xxxxxxxxxxint MPI_Attr_get(MPI_Comm comm, int keyval, void **attribute_val, int *flag)通过关键字得到属性值,如果没有具有值keyval的关键字,则调用出错,如果存在但没有属性则调用正确但flag=false,如果存在且有属性则调用正确flag=true
xxxxxxxxxxint MPI_Attr_delete(MPI_Comm comm, int keyval)将给定的关键字对应的属性值删除。
第十六章 具有虚拟进程拓扑的MPI程序设计
在许多并行应用程序中,进程的线性排列不能充分的反映进程在逻辑上的通信模型,进程通常被排列成二维或三维网格形式的拓扑模型,而且通常用一个图来描述逻辑进程排列,我们称逻辑进程排列为 “ 虚拟拓扑 ”
| 操作 | 笛卡尔拓扑 | 图拓扑 |
|---|---|---|
| 创建 | MPI_CART_CREATE | MPI_GRAPH_CREATE |
| 得到维数 | MPI_CARTDIM_GET | MPI_GRAPHDIMS_GET |
| 得到拓扑信息 | MPI_CART_GET | MPI_GRAPH_GET |
| 物理映射 | MPI_CART_MAP | MPI_GRAPH_MAP |
16.2 笛卡尔拓扑
笛卡尔拓扑用来描述任意维的笛卡尔结构。对于每一维,说明进程结构是否是周期性的。MPI_CART_CREATE返回一个指向新的通信域的句柄,这个句柄与笛卡尔拓扑信息相联系。
如果reorder=false,新进程组中每一个进程的标识数就和旧进程组的一样,否则会对进程重新编号。
该调用得到一个ndims维的处理器阵列,每一维分别包含
xxxxxxxxxxint MPI_Cart_creat(MPI_Comm comm_old, //输入通信域int ndims, //笛卡尔网格的维数int *dims, //大小为ndims的整数数组,定义每一维的进程数(整型数组)int *periods, //大小为ndims的逻辑数组,定义在一维上网格的周期性(逻辑数组)int reorder, //标识数是否可以重排顺序(逻辑型)MPI_Comm *comm_cart //带有新的笛卡尔拓扑的通信域)
xxxxxxxxxxint MPI_Dims_create( int nnodes, //网格中的结点数 int ndims, //笛卡尔维数 int *dims //大小为ndims的整数数组定义每一维的节点数)根据用户指定的总位数ndims和总的进程数nnodes,帮助用户在每一维上选择进程的个数。返回结果放在dims中,
xxxxxxxxxxint MPI_Topo_test( MPI_Comm comm, //通信域 int *status //通信域拓扑类型)返回给定通信域进程的拓扑类型,输出值为下面之一
MPI_GRAPH MPI_CART MPI_UNDEFINED 图拓展 笛卡尔拓展 没有定义拓展
xxxxxxxxxxint MPI_Cart_get( MPI_Comm comm, //带有笛卡尔结构的通信域 int maxdims, //最大维数 int *dims, //返回各维的进程数 int *periods, //返回各维的周期特性 int *coords //调用进程的笛卡尔坐标)返回给定通信域的拓扑信息,包括每一维的进程数dims,每一维的周期性periods和当前调用进程的笛卡尔坐标coords
xxxxxxxxxxint MPI_Cart_rank( MPI_Comm comm, //带有笛卡尔结构的通信域 int *coords, //卡氏坐标 int *rank //卡氏坐标对应的一维线性坐标)将给定拓扑的笛卡尔坐标转换成同一进程的用
MPI_COMM_RANK调用得到的顺序编号
xxxxxxxxxxint MPI_Cartdim_get(MPI_Comm comm, int *ndims)返回comm对应的笛卡尔结构的维数ndims
xxxxxxxxxxint MPI_Cart_shift( MPI_Comm comm, //带有笛卡尔结构的通信域 int direction, //需要平移的坐标维 int disp, //偏移量 int *rank_source, //源进程的卡氏坐标 int *rank_dest //目标进程的卡氏坐标 )将拓扑结构的通信域comm中的一个笛卡尔坐标rank_source,沿着指定维direction,以偏移量disp进行平移,得到的是调用进程的笛卡尔坐标,而调用进程的笛卡尔坐标经过同样的平移后,得到的是rank_dest。对于非周期性的拓扑,当超出返回后rank_source与rank_dest可以是MPI_PROC_NULL中返回
eg:通过MPI_Cart_shift(ring_comm,0,1,&left_nbr,&right_nbr)得到左右进程分别是多少
xxxxxxxxxxint MPI_Cart_coords( MPI_Comm comm, //带有笛卡尔结构的通信域 int rank, //一维线性坐标 int maxdims, //最大维数 int *coords //返回该一维线性坐标对应的卡氏坐标)将进程rank的顺序编号转换为笛卡尔坐标coords,其中maxdims是维数
xxxxxxxxxxint mPI_Cart_sub( MPI_Comm comm, //带有笛卡尔结构的通信域 int *remain_dims, //定义保留的维 MPI_Comm *newcomm //包含子网格的通信域,这个子网格包含了调用进程)将通信域划分成不同的子通信域,remain_dims指出保留的维,若remain_dims[i]是true则保留该维,若是false则划分为不同的通信域。
16.3 图拓扑
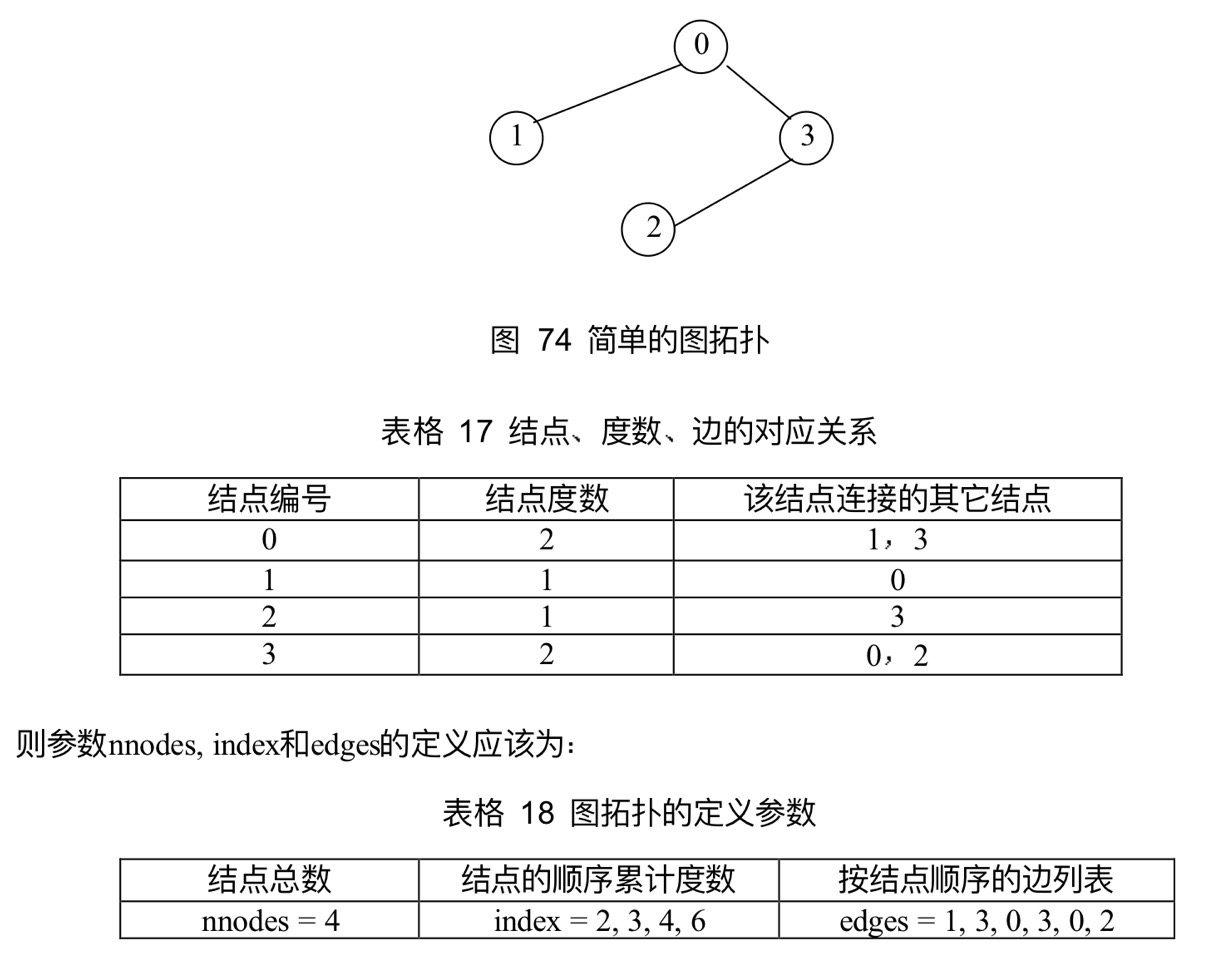
xxxxxxxxxxint MPI_Graph_create( MPI_Comm comm_old, //没有定义拓扑的通信域 int nnode, //图中包含的结点数 int *index, //结点的度数 int *edges, //图的边数 int reorder, //标识数是否可以重排序 MPI_Comm *comm_graph //定义了图拓扑的通信域)返回的通信域包含的拓扑结构是由nnodes、index、edges定义的图。reorder=false则新进程组中每个进程的标识数与旧进程组中的一致
index[0]是结点0的度数,index[i]-index[i-1]是结点i的度数
xxxxxxxxxxint MPI_Graphdims_get(MPI_Comm comm, int *nnodes, int *nedges)返回comm上定义的图的节点数nnodes和边数nedges
xxxxxxxxxxitn MPI_Graph_get(MPI_Comm comm, int maxindex, int maxedges)返回图对应的index
第十七章 MPI对错误的处理
17.1错误处理有关的调用
xxxxxxxxxxint MPI_Errhandler_creat( MPI_Handler_function *function, //用户定义的错误处理函数 MPI_Errhandler *errhandler //返回的MPI错误句柄)将用户function向MPI注册,作为一个MPI异常句柄,返回的errhandler是指向该注册的句柄
剩下略
(MPI的I/O在项目中已有所涉猎,这里不过多赘述)