

GPU并行大魔王之CUDA!!!
CUDA编程
GPU硬件架构综述
专业术语:
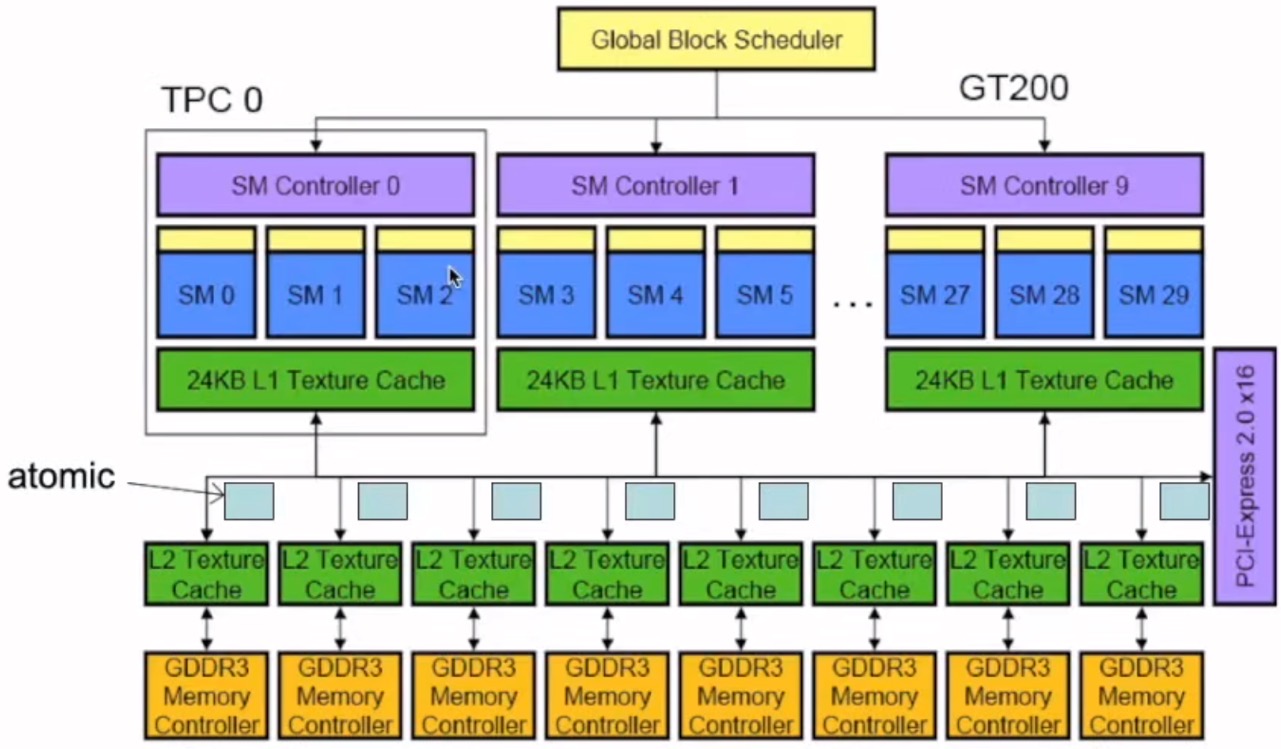
SPA:Streaming Processor Array (流式多处理器阵列)
TPC/GPC:Texture (Graphics) Processor Cluster (流式多处理器分成小组)
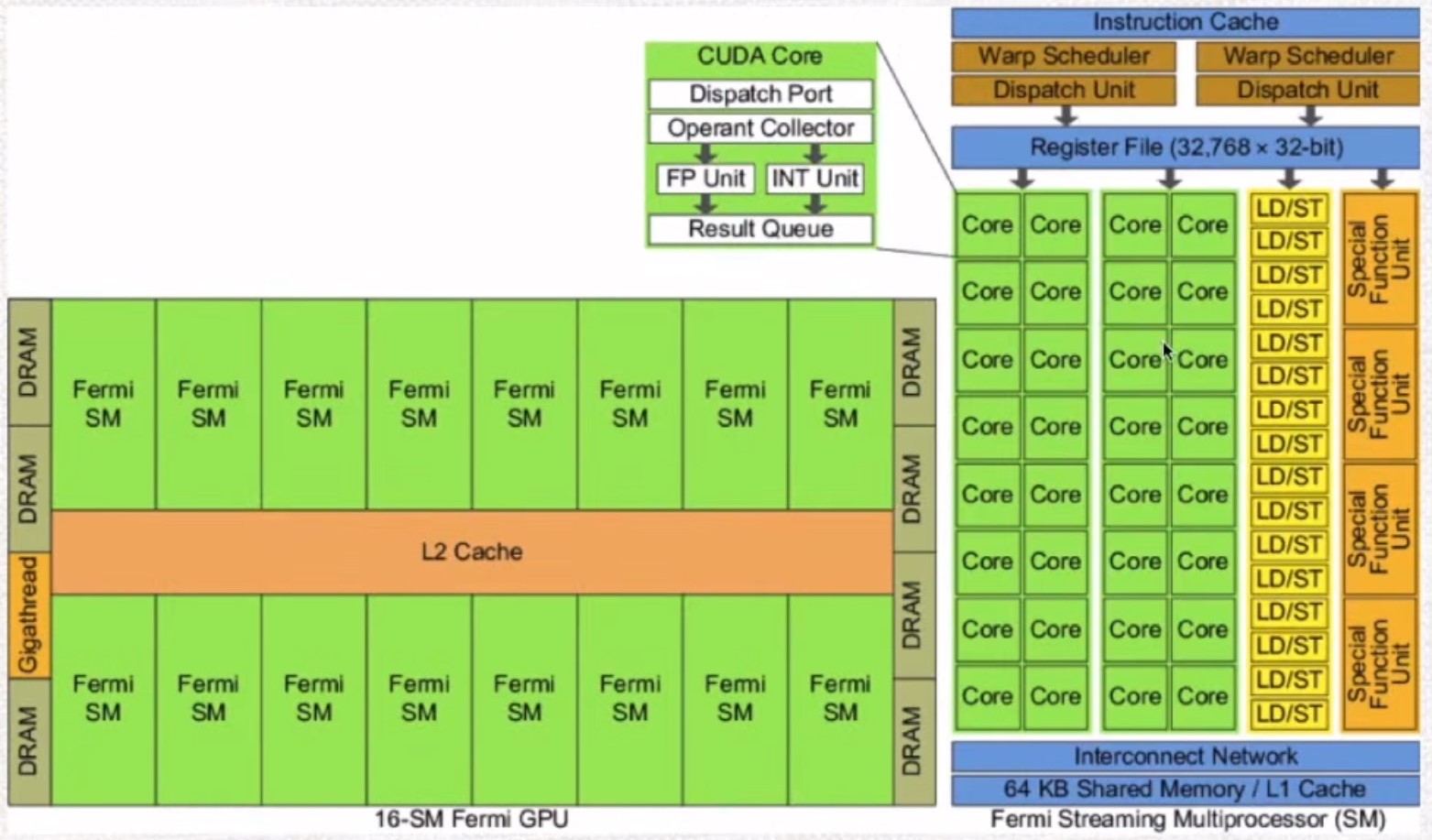
SM : Streaming Multiprocessor(32 SP)
Multi-threaded processor core
Fundamental processing unit for CUDA thread block
SP(CUDA Core):Streaming Processor 流处理器
共享内存远快于全局内存,但共享内存数据量比较小
一个块中,线程可以访问共享内存任意位置。
共享内存分为一个个Bank
如果访问Bank不冲突时,在一个时钟内可以完成数据读取,否则,冲突的线程按照顺序读取,在多个时钟内才能完成读取。
如果访问同一个地址可以考虑使用broadcast广播的方式。
Register File(RF) 寄存器
每个流多处理器都需要申请寄存器,每个块需要的寄存器越多,处于活跃状态的流多处理器比较少会降低并行度。
CUDA编程模型
GPU计算基础知识
- CUDA编程模型是一个异构模型(不同类型物体在完成同一件事),需要CPU和GPU协同工作
- CUDA中,host和device是分别指代CPU及其内存,和GPU及其内存
- CUDA程序中即包含host程序,也包含device程序,分别在CPU和GPU上运行
- host与device之间可以进行通信
CUDA程序执行流程
- 分配host内存,并进行数据初始化
- 分配device内存,并从host将数据拷贝到device上
- 调用CUDA的核函数在device上完成指定的运算
- 将device上的运算结果拷贝到host上(性能)
- 释放device和host上分配的内存
kernel是CUDA中一个重要概念,kernel是device上线程中并行执行的函数,核函数用
__global__[^双下划线]线号声明,在调用时需要用<<<grid,block>>>来指定kernel要执行的线程数,分别是grid中的block数以及block中的线程数,CUDA中每一个线程都要执行核函数,并且每个线程会分配一个唯一的线程号thread ID,这个ID值可以通过核函数内置变量threadIdx来获得
grid和block都是定义为dim3类型的变量,dim3可以看作包含三个无符号整数(x,y,z)成员的结构体变量,在定义时,缺省值初始化为1,grid和block可以灵活的定义为1-dim,2-dim,3-dim结构,不同的GPU架构,grid和block的维度有限制
such as:
dim3 grid(3,2);构造一个x上长度为3,y上长度为2,包含3X2个block的grid
dim3 block(5,3);构造一个x上长度为5,y上长度为3,包含5X3个thread的block在构造的时候最好总线程数是32的倍数,因为一个warp包含32个线程,一般以warp为单位进行工作
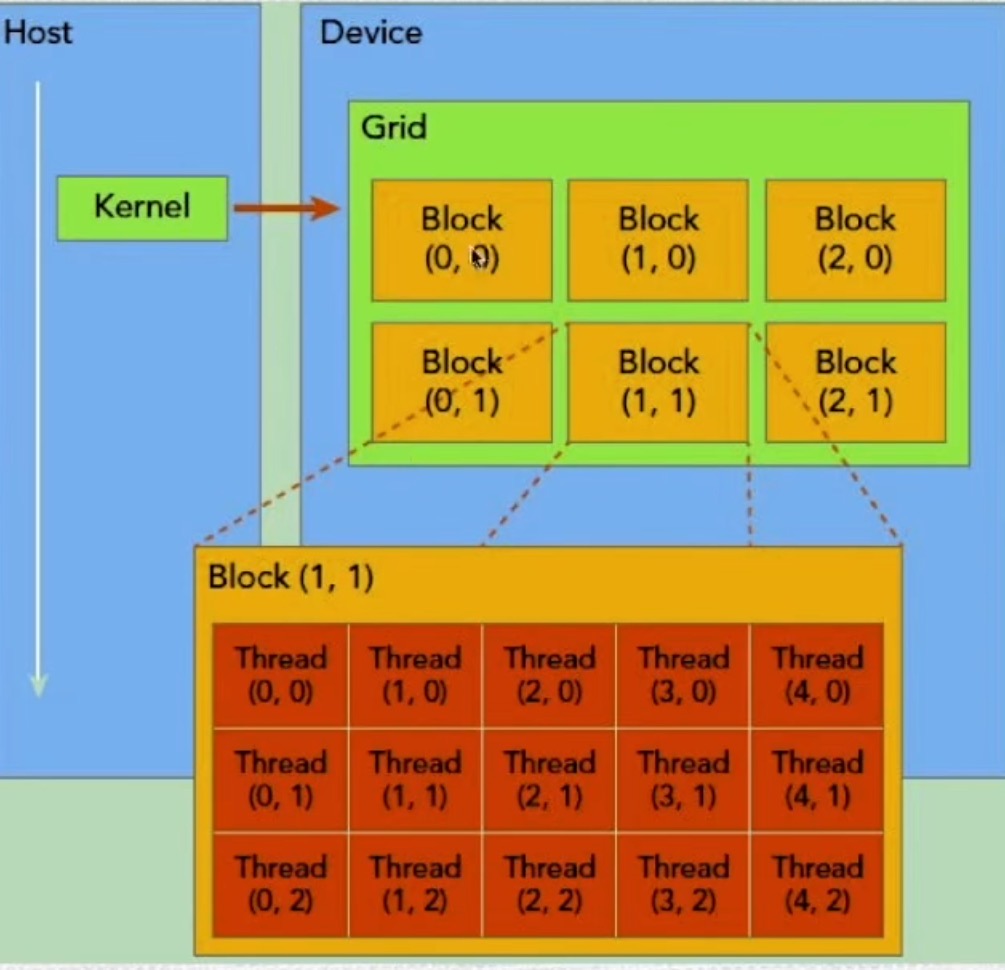
CUDA程序层次结构
- GPU上很多并行化的轻量级线程
- kernel在device上执行时实际上是启动很多线程,一个kernel所启动的所有线程称为一个网格(grid)
- 同一个网格上(grid)的线程共享相同的全局内存空间,grid是线程结构的第一层次
- 网格(grid)又可以分为很多线程块(block),一个线程块里面包含很多线程,这是第二个层次
- warp:32个线程一组,这是第三个层次
CUDA程序架构
GPU是异构模型,所以需要区分host和device上的代码,在CUDA中通过函数类型限定词区别host和device上的函数,主要的三个函数类型限定词:
__global__:在device上执行,从host中调用,返回类型必须是void,不支持可变参数,不能成为类成员函数。
用
__global__定义的kernel是异步的,host不会等待kernel执行完就执行下一步
__device__:在device上执行,单仅可以从device中调用,不可以和__global__同时用。__host__:在host上执行,单仅可以从host上调用,一般省略不写,不可以和__global__同时使用,但可以和__device__同时使用,此时函数会在device和host都编译。
CUDA内置变量
1、一个线程需要两个内置的坐标量 (blockIdx,threadIdx) 来唯一标识。它们都是dim3类型变量,其中blockIdx指明线程所在grid中的位置,而threadIdx指明线程所在block中的位置。
2、threadIdx包含三个值:threadIdx.x,threadIdx.y,threadIdx.z。
3、blockIdx同样包含三个值:blockIdx.x,blockIdx.y,blockIdx.z。
逻辑顺序 X>Y>Z , 块/线程顺序(0,0),(1,0),(2,0),(0,1),(1,1),(2,1)
4、一个线程块上的线程是放在同一个流多处理器 (SM) 上的。
5、单个SM资源有限,这导致线程块中的线程数是有限制的,现代GPUs的线程块可支持的线程数可达1024个。
6、我们要知道一个线程在block中的全局ID,此时就必须还要知道block的组织结构,通过线程内置变量blockDim来获取,它获取线程块各个维度的大小。
7、线程还内置gridDim来获取网格块各维度大小。
简单向量加
x//get thread id:1D block and 2D grid
//get block id:2D grid
__global__ void vec_add(double* x, double* y, double* z, int n){ int i = get_tid(); //user-defined function if(i<n) z[i]=x[i]+y[id];}
向量加法 程序解析
xxxxxxxxxx
typedef float FLOAT;
//get thread id:1D block and 2D grid
//get block id:2D grid
//启动预热GPUvoid warmup(){ int i; for(i=0;i<8;++i) warmup_knl<<<1,256>>>();}
//时间戳double get_time(void);
//host add c stylevoid vec_add_host(float *x, float *y, float *z, int N){ int i; for(i=0;i<N;++i) z[i]=z[i]+y[i]+x[i];}
//device function//Kernel定义__global__ void vec_add(float* x, float* y, float* z, int N){ //1D block int idx = get_tid(); //user-defined function 线程全局编号 if(i<N) z[idx]=x[idx]+y[idx]+z[idx];}
//系统编程double get_time(void){ struct timeval tv; double t; gettimeofday(&tv,(struct timezong*)0); t = tv.tv_sec + (double)tv.tv_usec*1e-6; return t;}
//省略windows系统计时函数定义
int main(){ int N=20000000; int nbytes=N*sizeof(float); int bs=256; //由于对于block和grid的每一维度都有最大限制,所以此处只能用二维的grid大小 int s=ceil(sqrt((N+bs-1)/bs)); //ceil()求不小于该浮点数的最小整数 dim3 grid=dim3(s,s); //二维grid float *dx=NULL, *hx=NULL; //d标识device h标识host float *dy=NULL, *hy=NULL; float *dz=NULL, *hz=NULL; int itr=30; int i; double th, td; warmup(); //allocate GPU mem cudaMalloc((void**)&dx, nbytes); cudaMalloc((void**)&dy, nbytes); cudaMalloc((void**)&dz, nbytes); if(dx == NULL||dy == NULL||dz == NULL){ printf("couldn't allocate GPU memory\n"); return -1; } printf("allocate %.2f MB on GPU\n", nbytes/(1024.f*1024.f)); //Init for(i=0;i<N;++i) { hx[i]=1;hy[i]=1;hz[i]=1; } //copy data to GPU cudaMemcpy(dx, hx, nbytes, cudaMemcpyHostToDevice); cudaMemcpy(dy, hy, nbytes, cudaMemcpyHostToDevice); cudaMemcpy(dz, hz, nbytes, cudaMemcpyHostToDevice); //warm up warmup(); //call GPU cudaThreadSynchronize(); //停住CPU等待GPU操作完成 td=get_time(); for(i=0;i<itr;++i) vec_add<<<grid,bs>>>(dx,dy,dz,N); cudaThreadSynchronize(); td=get_time()-td; //CPU th=get_time(); for(i=0;i<itr;++i) vec_add_host(hx,hy,hz,N); th=get_time()-th; printf("GPU time: %e, CPU time: %e, speedup: %g\n",td,th,th/td); cudaFree(dx);cudaFree(dy);cudaFree(dz); free(hx);free(hy);free(hz); //Kernel调用 vec_add<<<gs,bs>>>(x,y,z,N);}
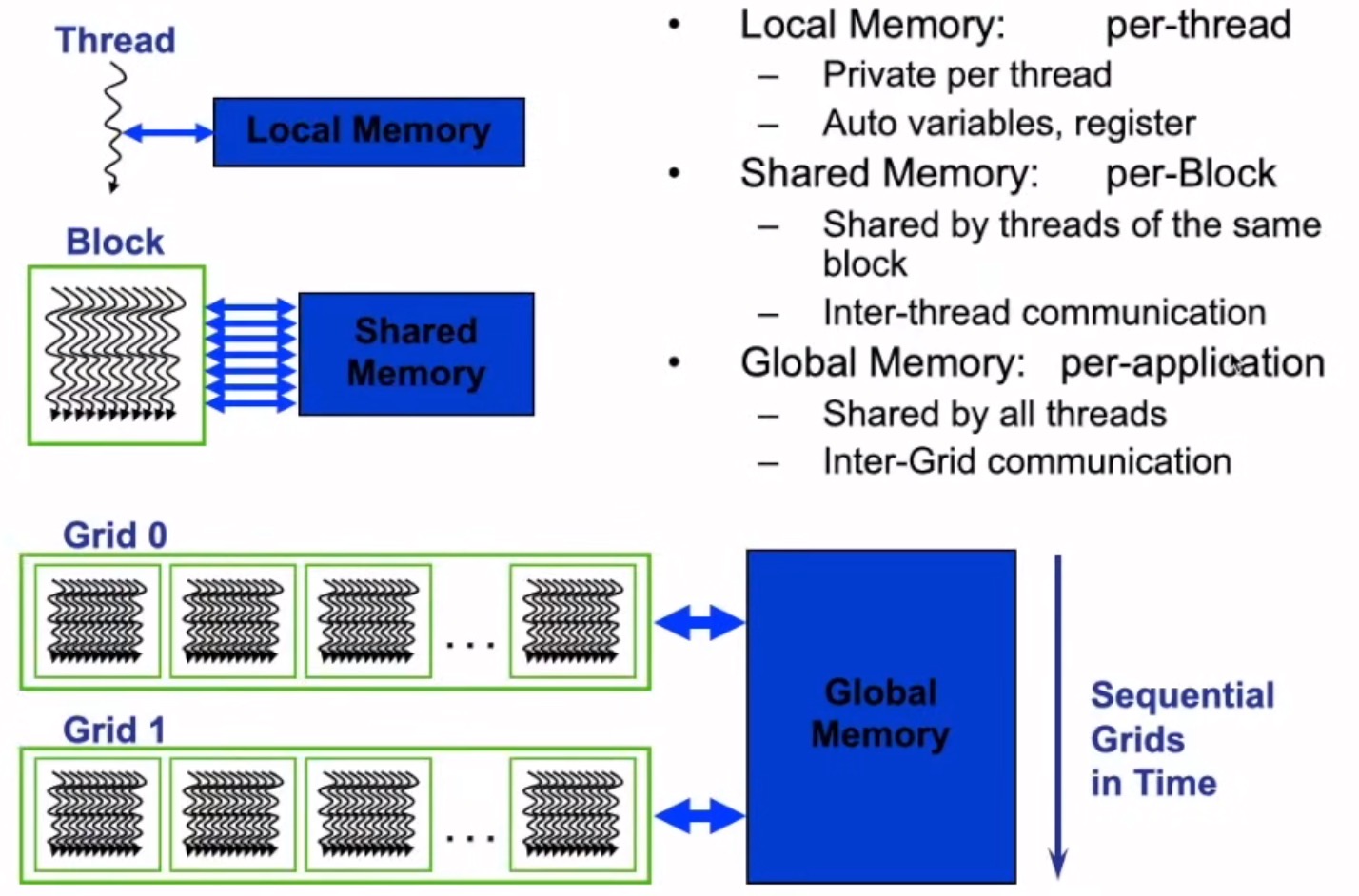
GPU内存模型
1、每个线程有自己私有本地内存(Local Memory)
2、每个线程块有包含共享内存(Shared Memory),可以被线程块中所有线程共享,其生命周期与线程块一致,速度比全局内存快得多
3、所有的线程都可以访问全局内存(Global Memory)
4、访问一些只读内存块:常量内存(Constant Memory)和纹理内存(Texture Memory)
5、L1 cache, L2 cache
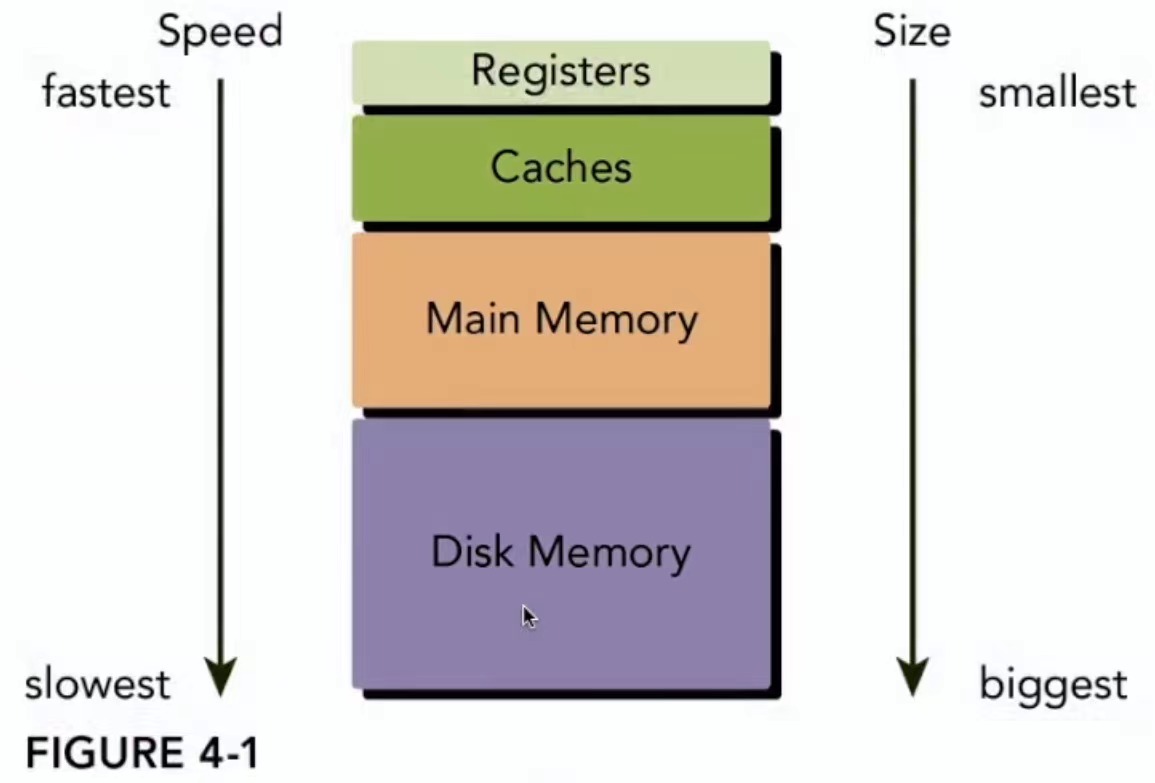
内存分为可编程内存和不可编程内存
- 可编程内存可以用代码来控制这组内存的行为
- 不可编程内存是不对用户开放的,其行为在出厂后就已经固化了,对于不可编程内存,我们能做的就是了解其原理,尽可能的利用规则加速程序
- CPU/GPU内存结构中,一级二级缓存都是不可编程(完全不可控制)的存储设备
内存作用域&生命周期
- 各种内存都有自己的作用域,生命周期和缓存行为
- CUDA中每个线程都有自己的私有的本地内存,寄存器
- 线程块有自己的共享内存,对线程块内所有线程可见
- 所有线程都能访问读取常量内存和纹理内存,但是不能写,因为它们是只读的
- 全局内存,常量内存和纹理内存空间有不同的用途。对于一个应用来说,全局内存,常量内存和纹理内存有相同的生命周期
寄存器
- 速度最快的内存空间,和CPU不同的是GPU的寄存器数量更多
- 当我们在核函数不加修饰的声明一个变量,此变量就存储在寄存器中
- 在核函数中定义的有常数长度的数组也是在寄存器中分配地址的
- 寄存器对于每个线程是私有的,寄存器通常保存被频繁使用的私有变量,寄存器变量的声明周期和核函数一致,从开始到运行结束,执行完毕后,寄存器就不能访问了
- 寄存器是SM中的稀缺资源,Fermi架构中每个线程最多63个寄存器。Kepler结构拓展到255个寄存器,一个线程如果使用更少的寄存器,那么就会有更多的常驻线程块,SM上并发的线程块越多,效率越高,性能和使用率也就越高
- 如果一个线程里面的变量太多,以至于寄存器完全不够,这时候寄存器就会溢出,本地内存就会帮助存储多出来的变量,这种情况对效率产生非常负面的影响
本地内存
核函数中符合存储在寄存器中但不能进入被核函数分配的寄存器空间中的变量将存储在本地内存中,编译器可能存放在本地内存中的变量有以下几种:
- 使用未知索引引用的本地数组
- 可能会占用大量寄存器空间的较大本地数组或者结构体
- 任何不满足核函数寄存器限定条件的变量
本地内存实质上是和全局内存一样在同一块存储区域当中的,其访问特点————延迟高,低带宽(带宽和宽带注意区分)。对于2.0以上的设备,本地内存存储在每个SM的以及缓存,或者设备的二级缓存上。
共享内存
核函数中使用如下修饰符的内存,称为共享内存:__shared__
每个SM都有一定数量的由线程块分配的共享内存,共享内存是块上的内存,和主存相比,速度快很多,延迟低,带宽高。类似于一级缓存,但是可以被编程
使用共享内存的时候一定要注意,不要因为过渡使用共享内存,而导致SM上活跃的线程束减少,一个线程块的使用的共享内存过多,导致更多的线程块没办法被SM启动,影响活跃的线程束数量
共享内存在核函数内声明,生命周期和线程块一致,线程块运行开始,此块的共享内存被分配,当此块结束,则共享内粗被释放。
共享内存是块内线程可见的,所以就有竞争问题的存在,也可以通过共享内存进行通信,为了避免内存竞争,可以使用同步语句:
语句相当于在线程块执行时各个线程的一个障碍点,当块内所有线程都执行到本障碍点的时候才能进行下一步的计算,但是该函数的频繁使用会影响内核执行效率
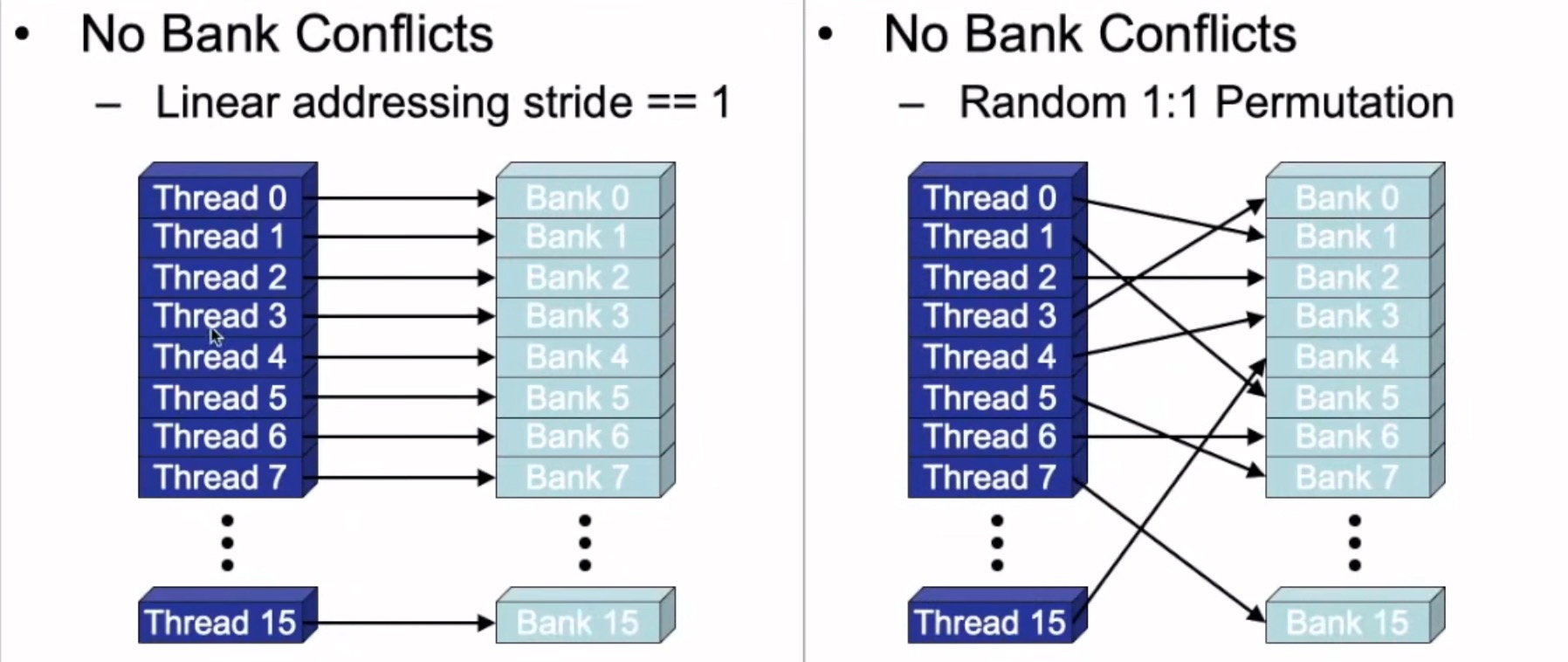
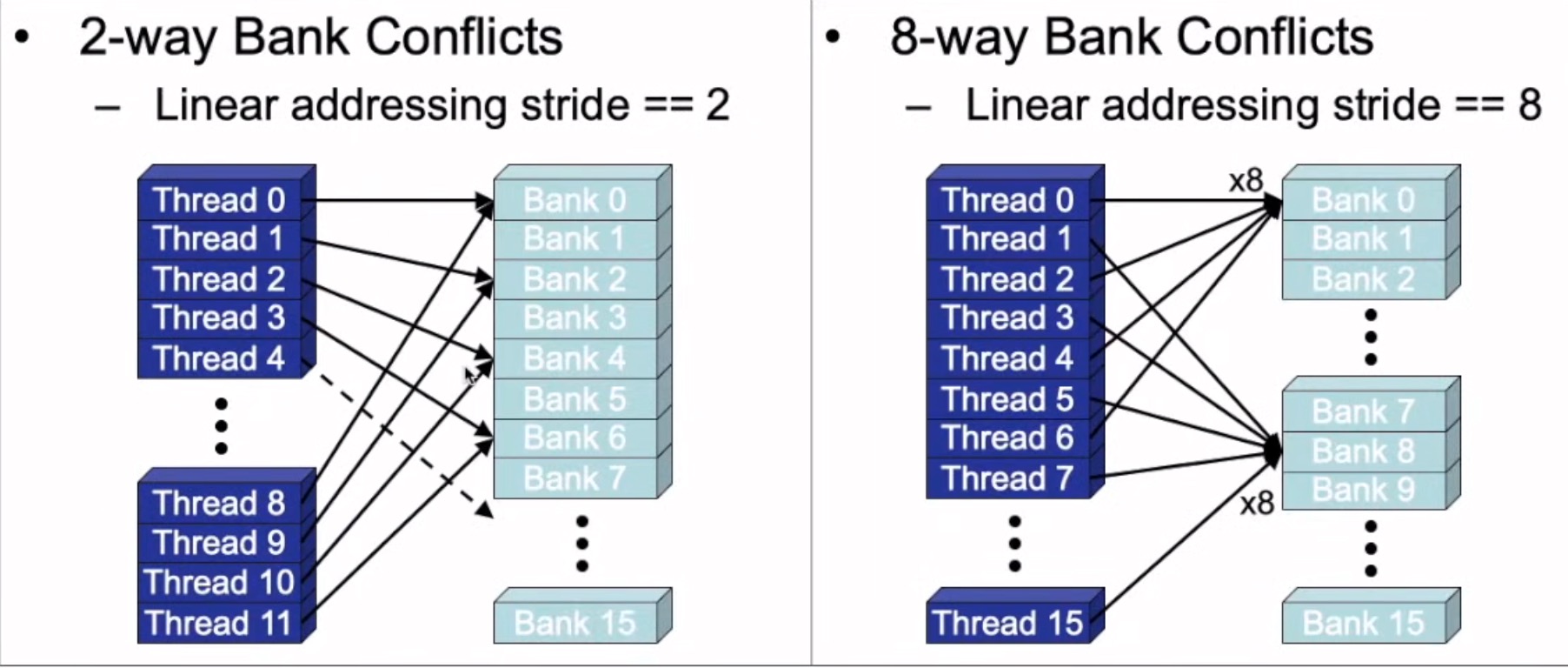
共享内存访问冲突
共享内存分成相同大小的内存块,实现高速并行访问
bank:是一种划分方式。在CPU中,访存时访问某个地址,获得地址上的数据,但是在这里,是一次性访问banks数量的地址,获得这些地址上的所有数据,并逻辑映射到不同的bank上,类似内存读取的控制。
为了事项内存高带宽的同时访问,shared memory被划分成了可以同时访问的等大小内存块(banks)。因此,内存读写n个地址的行为则可以以b个独立的bank同时操作的方式进行,这样有效带宽就提高到一个bank的b倍
如果多个线程请求的内存地址被映射到同一个bank上,那么这些请求就变成了串行的(serialized)。硬件将把这些请求分成x个没有冲突的请求序列,带宽就降低成立原来的
。但是如果一个warp内的所有线程都访问同一个内存地址的话,会产生一次广播(boardcast),这些请求就会一次完成。计算能力2.0及以上的设备也具有组播(multicast)能力,可以同时响应同一个warp内访问同一个内存地址的部分线程的请求。
常量内存
常量内存驻留在设备内存中,每个SM都有专用的常量内存缓存,常量内存使用:
常量内存在核函数外,全局范围内声明,对于所有设备,只可以声明一定数量的常量内存,常量内存静态声明,并对同一编译单元中的所有核函数可见。常量内存不能被核函数修改,主机端代码可以初始化常量内存。
纹理内存
纹理内存驻留在设备内存中,在每个SM的只读缓存中缓存,纹理内存是通过指定的缓存访问的全局内存,只读缓存包括硬件滤波的支持,纹理内存设计目的是为了GPU显示,但对于某些特定的程序效果更好,比如需要滤波的程序,可以直接通过硬件
全局内存
独立于GPU核心的硬件RAM,GPU绝大多数内存空间都是全局内存,通过cache L2访问,全局内存的I/O是GPU上最慢的I/O形式(除了访问host端)GPU上最大的内存空间,延迟最高,使用最常见的内存,global指的是作用域和生命周期,一般在主机端代码里定义,也可以在设备端定义,不过需要加修饰符
GPU内存如何管理
- CUDA程序会使用GPU内存与CPU内存
- CPU内存的分配与释放是标准的,例如new和delet, malloc与free
- GPU上内存涉及分配和释放,使用CUDA提供的库函数实现
- CUDA/GPU内存与CPU内存的互相传输
GPU全局内存分配释放
- 内存分配
- 内存释放
Host内存分配释放
Host内存属于CPU内存,传输速度比普通CPU内存快很多
- 内存分配
- 内存释放
统一(Unified)内存分配释放
Unified内存可以同时被CPU与GPU访问
- 内存分配
flags=cudaMemAttachGlobal:内存可以被任意处理器访问(GPU,CPU)
flags=cudaMemAttachHost:只可以CPU访问
- 内存释放
CPU与GPU内存同步拷贝
Kind:cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToDevice, cudaMemcpyDeviceToHost, cudaMemcpyDefault
CPU与GPU内存异步拷贝
kind同上,stream如果非0可能与其他stream的操作有重叠
共享内存
- 定义在SM中
访问延迟比全局内存低两个数量级,访问速度比全局内存快一个数量级
- 共享内存是定义在线程块中,线程块中每个线程都可以访问,但不可以被其他线程块访问
内存管理代码解析
xxxxxxxxxx//向量每个元素加一
__global__ void sum(double *x){ //只使用一个block所以不需要计算全局编号 int tid=threadIdx.x; x[tid]+=1;}
int main(){ int N=32; //向量32个元素 int nbytes=N*sizeof(double); double *dx=NULL,*hx=NULL; int i; //allocate GPU mem cudaMalloc((void **)&dx, nbytes); //GPU上分配内存 if(dx==NULL){printf("couldn't allocate memory");return -1;} //allocate CPU mem //使用Hostmem分配获得更快的传输速度 cudaMallocHost((void**)&hx, nbytes); //hx=(double*)malloc(nbytes); if(hx==NULL){printf("couldn't allocate memory");return -2;} //init printf("hx original:\n"); for(i=0;i<N;++i) { hx[i]=i; printf("%g\n",hx[i]); } //copy data to GPU cudaMemcpy(dx, hx, nbytes, cudaMemcpyHostToDevice); //call GPU sum<<<1,N>>>(dx); //let GPU finish cudaThreadSynchronize(); //同步所有线程 //copy data from GPU cudaMemcpy(hx, dx, nbytes, cudaMemcpyDeviceToHost); printf("\nhx from GPU:\n"); for(i=0;i<N;++i) printf("%g\n",hx[i]); cudaFree(dx); //如果使用hostmem分配释放用下面这条 //cudaFreeHost(hx); free(hx); return 0;}
CUDA程序执行与硬件映射
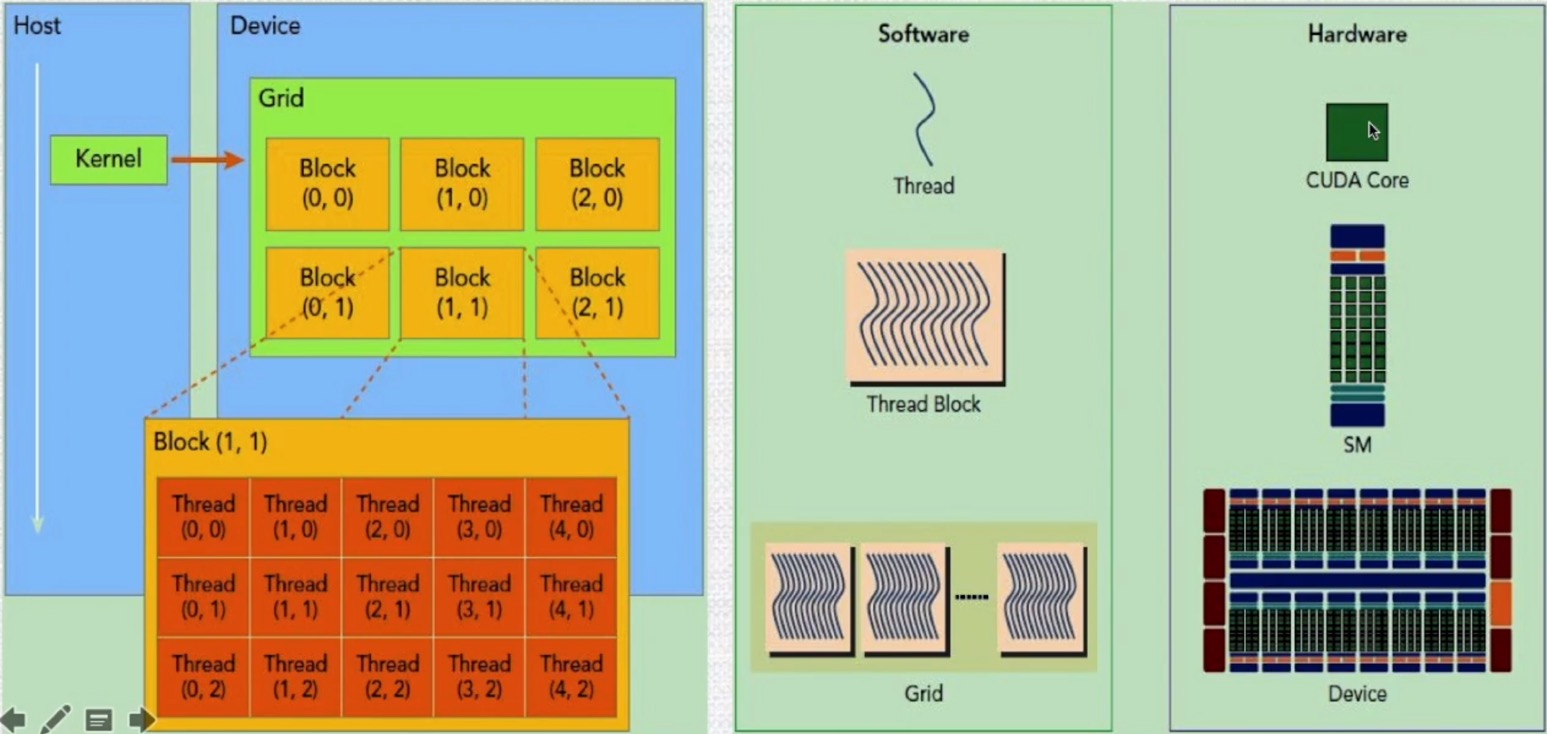
GPU流式多处理器
- 一个kernel实际上会启动很多线程,这些线程是逻辑上并行的,但是在物理层却并不一定
- GPU硬件的一个核心组件是SM(Streaming Multiprocessor)流式多处理器
- SM的核心组件包括CUDA核心,共享内存,寄存器等,SM可以并发的执行数百个线程,并发能力取决于SM拥有资源
- 当一个kernel被执行时,它的grid中的线程块被分配到SM上,一个线程块只能在一个SM上被调度
- SM一般可以调度多个线程块。可能一个kernel的各个线程块被分配多个SM,所以grid只是逻辑层,SM才是执行的物理层
WARP技术细节
- SM采用的是SIMT(单指令多线程)架构,基本的执行单元是线程束(warp),线程束包含32个线程
- 线程同时执行相同的指令,但是每个线程都包含自己的指令地址计数器和寄存器状态,也有自己独立的执行路径
- 线程束中的线程同时从同一程序地址执行,但是可能具有不同的行为,如遇到了分支一些线程进入分支,另一些不执行
- GPU规定线程束中所有线程在同一周期执行相同的指令,线程束分化会导致性能下降
性能优化
- 当线程块被划分到某个SM上时,它将进一步划分为多个线程束(warp),它才是SM执行的基本单元
- 因为资源限制,一个SM同时并发的线程束是有限的,SM为每个线程块分配共享内存(用户自定义共享内存剩下的自由共享内存),而也要为每个线程束中的线程分配独立的寄存器,所以SM的配置会影响其所支持的线程块和线程束并发数量
- grid和block只是逻辑划分,一个kernel的所有线程其实在物理层是不一定同时并发的
- kernel的grid和block的配置不同,性能会出现差异,这点需注意
- 由于SM的基本执行单元是包含32个线程的线程束,所以block大小一般要设置为32的倍数
规约算法
我们经常将多个值编程一个值(例如加减乘除取余)
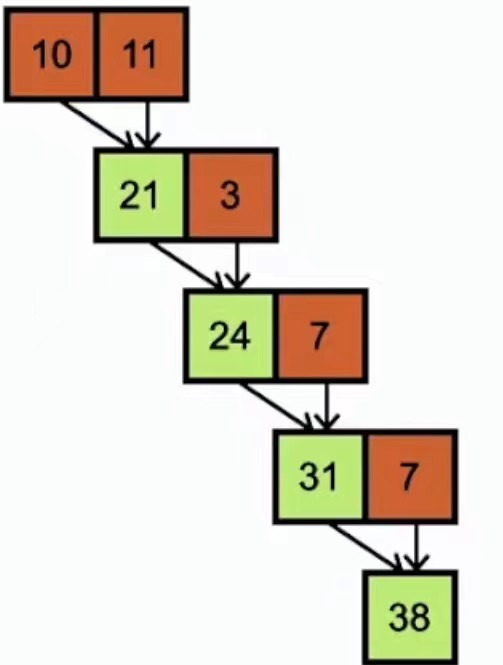
串行执行加法运算如上如所示,复杂度O(N)
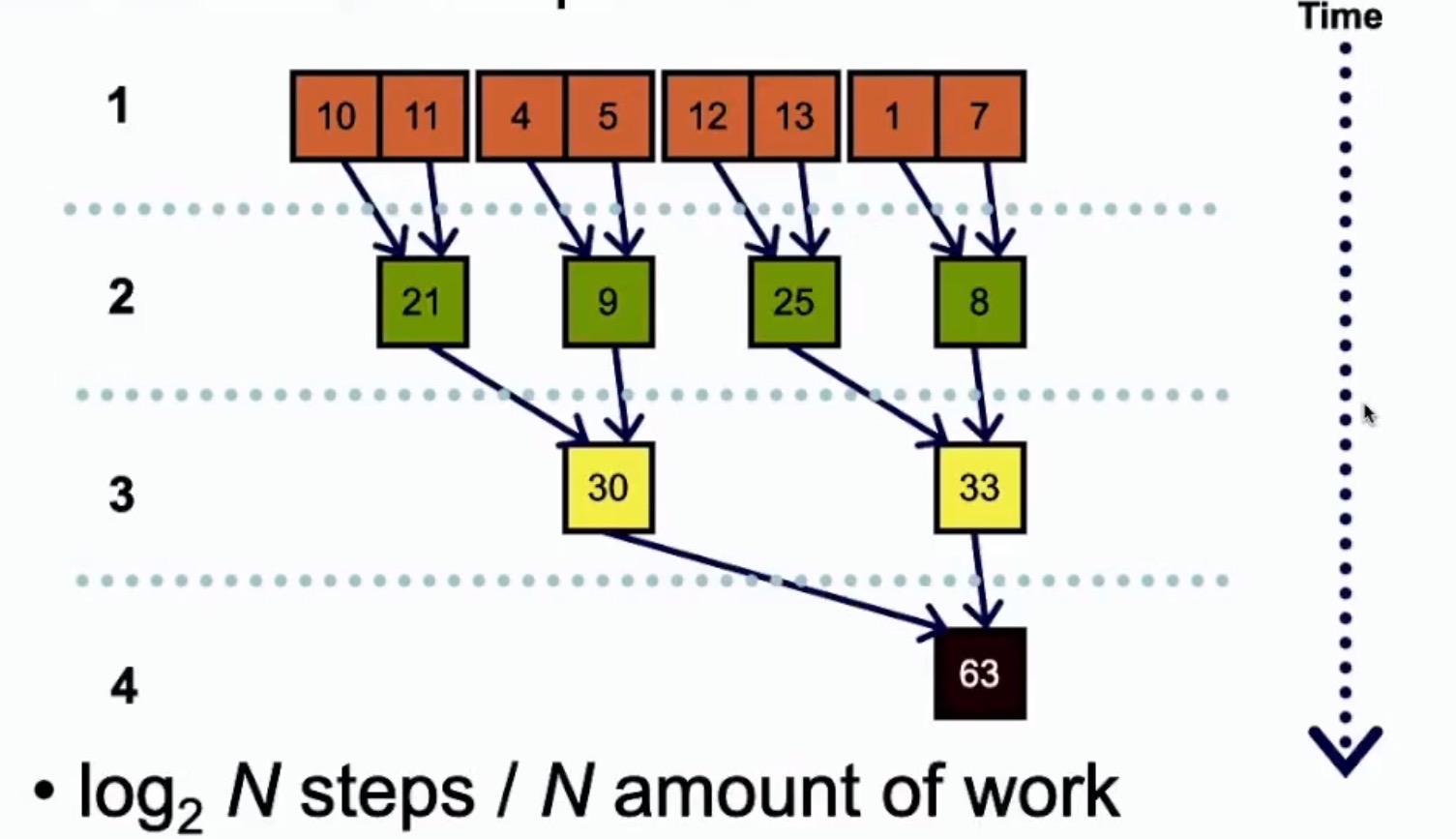
二叉树的方式加法
GPU编程时,只启动单个块会造成其他计算资源的浪费,所以可以启动多个块,每个块负责向量不同的部分,类似MPI中文件视口的方式
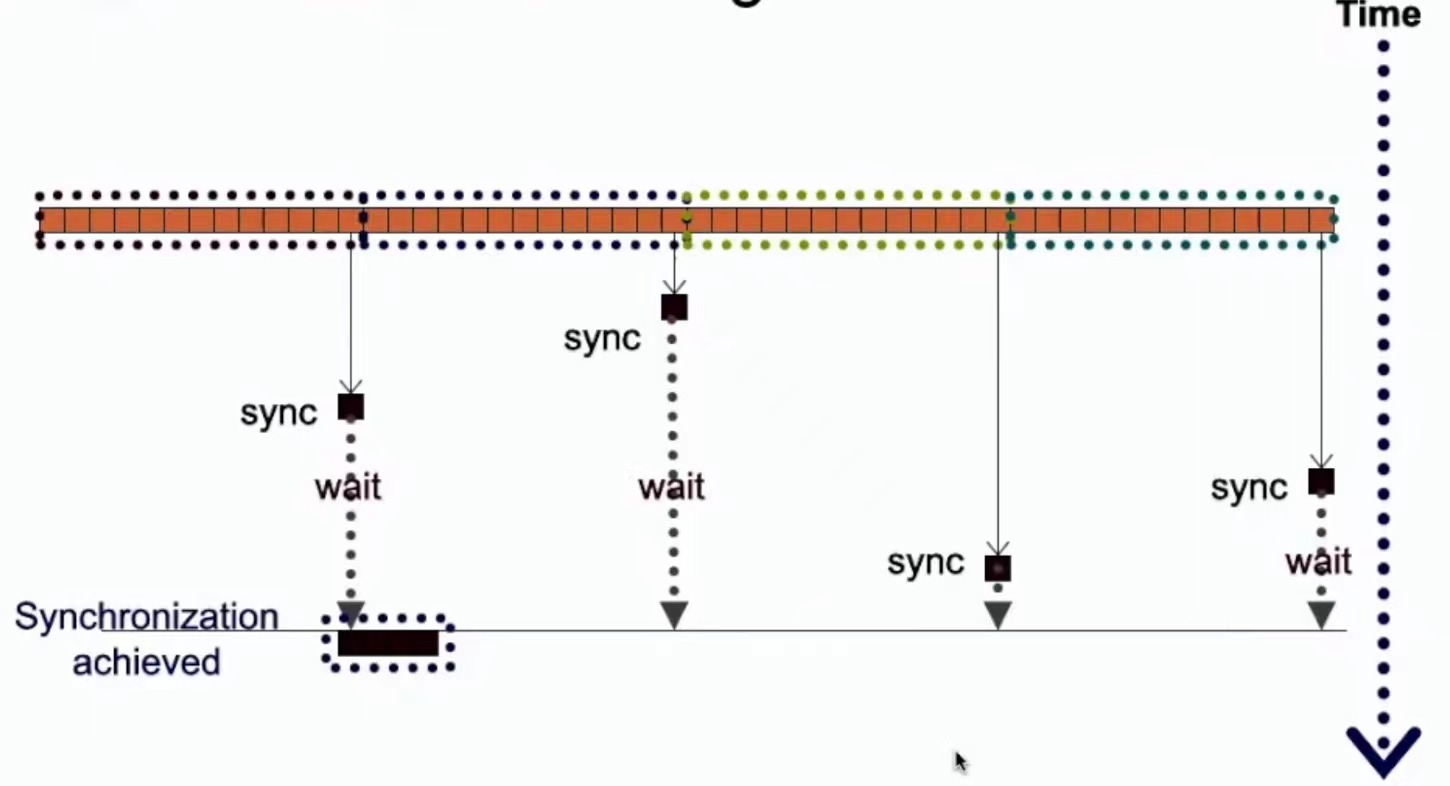
使用同步的方式让所有块都计算完成,然后开始互通结果
但是CUDA不支持全局同步

CUDA不支持全局同步,因为处于等待别的块时,块处于限制状态会造成计算资源浪费,并且如果SM都处于等待状态需要执行的程序找不到闲置资源会导致死锁
当启动下一个kernel时,会隐性的等待上一个kernel所有线程执行结束,利用这个特性可以实现全局同步
二叉树
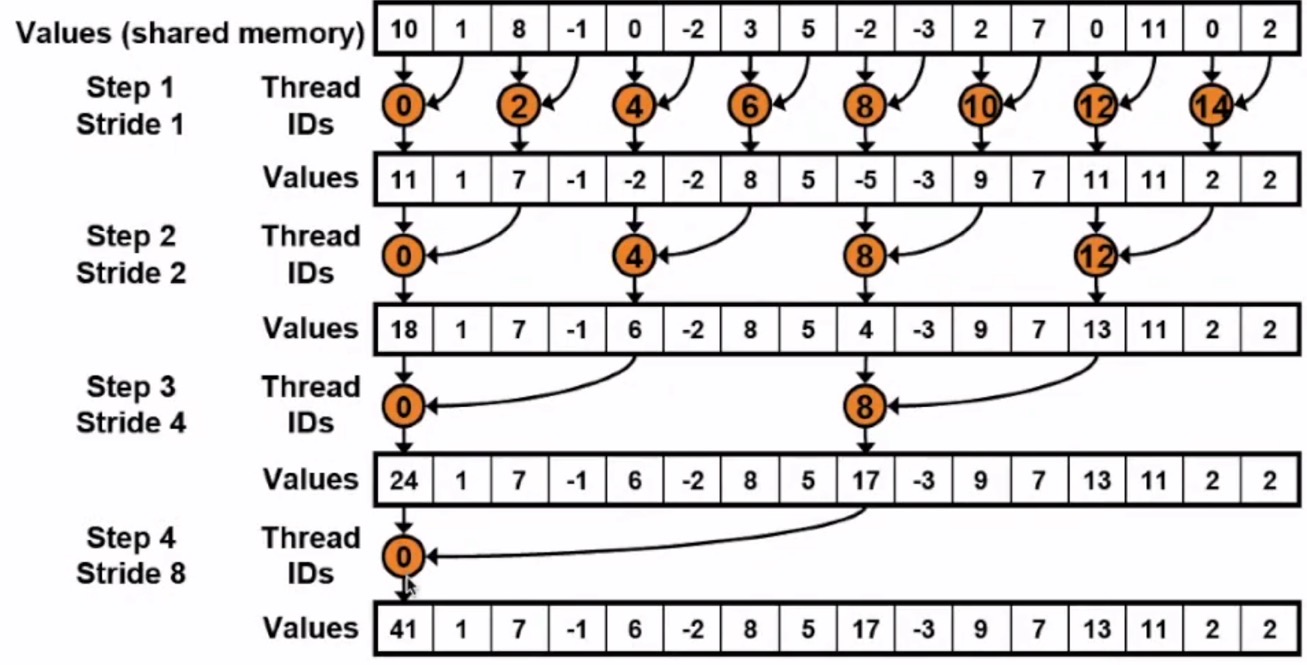
xxxxxxxxxx__global__ void reduce(int *g_idata, int *g_odata){ extern __shared__ int sdata[]; //共享内存 //每个线程加载一个元素到共享内存中 unsigned int tid = threadIdx.x; unsigned int i = blockIdx.x*blockDim.x+threadIdx.x; sdata[tid]=g_idata[i]; //此处sdata应该是每个block的共享内存 __syncthreads(); //二叉算法在共享内存 for(unsigned int s=1;s<blockDim.x;s*=2) //循环次数即一共需要计算多少轮(二叉树深度) { if(tid%(2*s)==0) //每一轮能参与计算的数据 { //只有可以被整除的线程参与 sdata[tid]+=sdata[tid+s]; } __synthreads(); } //将结果写入全局内存 if(tid==0) g_odata[blockIdx.x]=sdata[0];}
warp的启动情况

改进warp divergence
如果同一个warp中的线程执行的命令不一样,那么不同的部分就会以串行的方式运行,严重影响运行性能
这里为什么要这样改正!!!!!
首先在启动线程的时候,并不能指定warp,而是只能指定grid和block,但是编程的时候需要考虑warp,第一种情况工作的线程不是连续的,线程中间会有休息的,并且会占用更多的warp,而第二种改进版本,连续的线程在工作,所有一块warp都在工作且是同一个算法
同时解决bank冲突的问题(bank conlicts 多个线程访问一个bank里的不同地址)
xxxxxxxxxx__global__ void reduce(int *g_idata, int *g_odata){ extern __shared__ int sdata[]; //共享内存 //每个线程加载一个元素到共享内存中 unsigned int tid = threadIdx.x; unsigned int i = blockIdx.x*blockDim.x+threadIdx.x; sdata[tid]=g_idata[i]; //此处sdata应该是每个block的共享内存 __syncthreads(); //二叉算法在共享内存 //for(unsigned int s=1;s<blockDim.x;s*=2) //循环次数即一共需要计算多少轮(二叉树深度) //{ // if(tid%(2*s)==0) //每一轮能参与计算的数据 // { // //只有可以被整除的线程参与 // sdata[tid]+=sdata[tid+s]; // } // __synthreads(); //} //对注释掉的部分代码进行修改 for(unsigned int s=1;s<blockDim.x;s*=2) { int index = 2*s*tid; //引入变量,防止代码不一样,引起的变为串行执行 if(index<blockDim.x/s) // /s是用来限制线程编号的,和之前的区别在于,这里做计算的线程是0、1、2、3连续的线程 sdata[index]+=sdata[index+s]; } __syncthreads(); //将结果写入全局内存 if(tid==0) g_odata[blockIdx.x]=sdata[0];}

改进后warp启动情况

改进共享内存访问,消除冲突
bank的中文翻译为存储体,GPU共享内存是基于存储体切换的架构(bank-switched-architecture),一般现在的GPU都包含32个存储体,即共享内存被分成了32个bank
如果一个warp的多个线程访问同一个bank的不同字段时(注:不同字段如bank[0] [0],bank[1] [0],...,bank[n] [0]),那么就发生了bank冲突,因为不同bank可以同时访问,而当如果多个线程请求的内存地址被映射到了同一个bank上,那么这些请求就变成了串行的
注:不同的访问同一个bank时会发生冲突,不同bank可以同时访问,且bank一般是32个,每个bank32位,所以一般将数据存储在不同bank中,同一个warp中线程访问不同的bank。访问同一个bank中同一元素时boardcast解决。
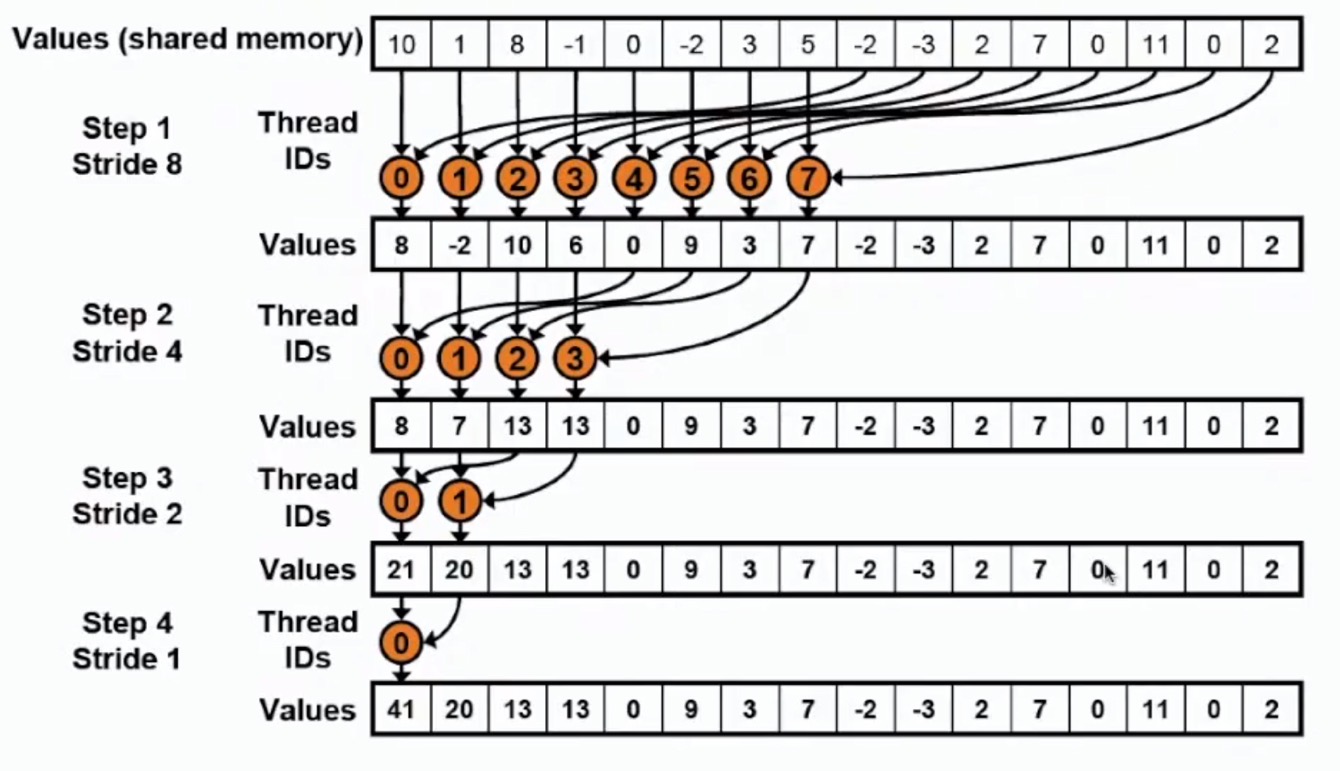
虽然是小规模,但是当大规模运行的时候就会有很明显提升。
继续修改
xxxxxxxxxx__global__ void reduce(int *g_idata, int *g_odata){ extern __shared__ int sdata[]; //共享内存 //每个线程加载一个元素到共享内存中 unsigned int tid = threadIdx.x; unsigned int i = blockIdx.x*blockDim.x+threadIdx.x; sdata[tid]=g_idata[i]; //此处sdata应该是每个block的共享内存 __syncthreads(); //二叉算法在共享内存 //for(unsigned int s=1;s<blockDim.x;s*=2) //循环次数即一共需要计算多少轮(二叉树深度) //{ // if(tid%(2*s)==0) //每一轮能参与计算的数据 // { // //只有可以被整除的线程参与 // sdata[tid]+=sdata[tid+s]; // } // __synthreads(); //} //for(unsigned int s=1;s<blockDim.x;s*=2) //{ // int index = 2*s*tid; //引入变量,防止代码不一样,引起的变为串行执行 // if(index<blockDim.x/s) // /s是用来限制线程编号的,和之前的区别在于,这里做计算的线程是0、1、2、3连续的线程 // sdata[index]+=sdata[index+s]; //} //对注释掉的部分代码进行修改 for(unsigned int s=block.Dim.x/2;s>0;s/=2) { if(tid<s) { sdata[tid]+=sdata[tid+s]; } } __syncthreads(); //将结果写入全局内存 if(tid==0) g_odata[blockIdx.x]=sdata[0];}
改进从全局内存访问
从全局内存加载两个数据到共享内存
xxxxxxxxxxunsigned int tid= threadIdx.x;unsigned int i=blockIdx.x*blockDim.x*2+threadIdx.x;sdata[tid]=g_idata[i]+g_idata[i+blockDim.x]; //第0个block和第1个block做加法,第2个和第3个block做加法__syncthreads();
warp内循环展开
循环展开,可以同时运行,而且避免了变量的更新,变量的比较。
xxxxxxxxxx __global__ void reduce(int *g_idata, int *g_odata){ extern __shared__ int sdata[]; //共享内存 //每个线程加载一个元素到共享内存中 unsigned int tid = threadIdx.x; unsigned int i = blockIdx.x*blockDim.x+threadIdx.x; sdata[tid]=g_idata[i]; //此处sdata应该是每个block的共享内存 __syncthreads(); // //for(unsigned int s=block.Dim.x/2;s>0;s/=2) //{ // if(tid<s) // { // sdata[tid]+=sdata[tid+s]; // } //} //对于注释部分进行修改 for(unsigned int s=blockDim.x/2;s>32;s/=2) { //结束条件是s=32时,即还有64个线程的时候,此时只剩下64个数,用一个warp操作即可 if(tid<s) sdata[tid]+=sdata[tid+s]; __syncthreads(); } if(tid<32) //最后一个warp时同步执行 有点没理解这段代码???? { //每个线程同时执行且按顺序执行命令,如所有线程先执行sdata[tid]+=sdata[tid+32]; sdata[tid]+=sdata[tid+32]; sdata[tid]+=sdata[tid+16]; sdata[tid]+=sdata[tid+8]; sdata[tid]+=sdata[tid+4]; sdata[tid]+=sdata[tid+2]; sdata[tid]+=sdata[tid+1]; } __syncthreads(); //将结果写入全局内存 if(tid==0) g_odata[blockIdx.x]=sdata[0];}
完全循环展开
CUDA支持C++的模板,利用这个模板就可以将循环完全展开,用模板写出通用kernel
xxxxxxxxxxtemplate <unsigned int blockSize> //表示块的大小 调用时传入__global__ void reduce5(int *g_data,int *g_odata) //不超过512个线程时都可以运行{ if(blockSize>=512) { if(tid<256){sdata[tid]+=sdata[tid+256];}__syncthreads(); } if(blockSize>=256) { if(tid<128){sdata[tid]+=sdata[tid+128];}__syncthreads(); } if(blockSize>=128) { if(tid<64){sdata[tid]+=sdata[tid+64];}__syncthreads(); } if(tid<32) //最后一个warp时同步执行 有点没理解这段代码???? { //每个线程同时执行且按顺序执行命令,如所有线程先执行sdata[tid]+=sdata[tid+32]; if(blockSize>=64)sdata[tid]+=sdata[tid+32]; if(blockSize>=32)sdata[tid]+=sdata[tid+16]; if(blockSize>=16)sdata[tid]+=sdata[tid+8]; if(blockSize>=8)sdata[tid]+=sdata[tid+4]; if(blockSize>=4)sdata[tid]+=sdata[tid+2]; if(blockSize>=2)sdata[tid]+=sdata[tid+1]; }}
xxxxxxxxxx//调用部分switch(threads){ case 512: reduce5<512><<<dimGrid,dimBlock,smemSize>>>(d_idata,d_odata);break; case 256: reduce5<256><<<dimGrid,dimBlock,smemSize>>>(d_idata,d_odata);break; case 128: reduce5<128><<<dimGrid,dimBlock,smemSize>>>(d_idata,d_odata);break; case 64: reduce5<64><<<dimGrid,dimBlock,smemSize>>>(d_idata,d_odata);break; case 32: reduce5<32><<<dimGrid,dimBlock,smemSize>>>(d_idata,d_odata);break; case 16: reduce5<16><<<dimGrid,dimBlock,smemSize>>>(d_idata,d_odata);break; case 8: reduce5<8><<<dimGrid,dimBlock,smemSize>>>(d_idata,d_odata);break; case 4: reduce5<4><<<dimGrid,dimBlock,smemSize>>>(d_idata,d_odata);break; case 2: reduce5<2><<<dimGrid,dimBlock,smemSize>>>(d_idata,d_odata);break; case 1: reduce5<1><<<dimGrid,dimBlock,smemSize>>>(d_idata,d_odata);break;
}
volatile 关键字声明,避免编译器内部优化(such as求和方式顺序等)相反降低性能或错误,例如
xxxxxxxxxx__shared__ volatile FLOAt sdata[256];//或者__device__ void warpReduce(volatile FLOAT *sdata, int tid)
规约算法应用:内积
内积:
三阶段算法:
- 1.块大小:256 数组长度降低256倍
- 2.对部分和 继续使用上一步的算法
- 3.使用一个块,将最后结果规约
具体见example板块
xxxxxxxxxx//第一阶段__global__ void dot_stg_1(const FLOAT *x, FLOAT *y, FLOAT *z,int N){ __shared__ FLOAT sdata[256]; int idx=get_tid(); int tid=threadIdx.x; int bid=get_bid(); //加载数据到共享内存 if(idx<N) sdata[tid]=x[idx]*y[idx]; else sdata[tid]=0; __synthreads(); //使用共享内存合并 if(tid<128)sdata[tid]+=sdata[tid+128]; __synthreads(); if(tid<64)sdata[tid]+=sdata[tid+64]; __synthreads(); if(tid<32)warpReduce(sdata,tid); if(tid==0)z[bid]=sdata[0];}
//对x中所有条目求和,并对齐y//block的dim必须是256
//第二阶段__global__ void dot_stg_2(const FLOAT *x,FLOAT *y,int N){ __shared__ FLOAT sdata[256]; int idx=get_tid(); int tid=threadIdx.x; int bid=get_bid(); //加载数据到共享内存 if(idx<N) sdata[tid]=x[idx]; else sdata[tid]=x[tid]; __synthreads(); if(tid<128)sdata[tid]+=sdata[tid+128]; __synthreads(); if(tid<64)sdata[tid]+=sdata[tid+64]; __synthreads(); if(tid<32)warpReduce(sdata,tid); if(tid==0)y[bid]=sdata[0];}
//第三阶段 用一块将结果加起来__global__ void dot_stg_3(FLOAT *x,int N){ __shared__ FLOAT sdata[128]; int i; int tid=threadIdx.x; sdata[tid]=0; //加载数据到共享内存 for(i=0;i<N;i+=128) if(tid+i<M)sdata[tid]+=x[i+tid]; __synthreads(); /* reduction using shared mem */ if (tid < 64) sdata[tid] = sdata[tid] + sdata[tid + 64]; __syncthreads();
if (tid < 32) warpReduce(sdata, tid);
if (tid == 0) x[0] = sdata[0];
xxxxxxxxxx__device__ void warpReduce(volatile FLOAT *sdata, int tid){ sdata[tid] += sdata[tid + 32]; sdata[tid] += sdata[tid + 16]; sdata[tid] += sdata[tid + 8]; sdata[tid] += sdata[tid + 4]; sdata[tid] += sdata[tid + 2]; sdata[tid] += sdata[tid + 1];}
xxxxxxxxxx/* dz and d serve as cache: result stores in d[0] */void dot_device(FLOAT *dx, FLOAT *dy, FLOAT *dz, FLOAT *d, int N){ /* 1D block */ int bs = 256;
/* 2D grid */ int s = ceil(sqrt((N + bs - 1.) / bs)); dim3 grid = dim3(s, s); int gs = 0;
/* stage 1 */ dot_stg_1<<<grid, bs>>>(dx, dy, dz, N);
/* stage 2 */ { /* 1D grid */ int N2 = (N + bs - 1) / bs;
int s2 = ceil(sqrt((N2 + bs - 1.) / bs)); dim3 grid2 = dim3(s2, s2);
dot_stg_2<<<grid2, bs>>>(dz, d, N2);
/* record gs */ gs = (N2 + bs - 1.) / bs; }
/* stage 3 */ dot_stg_3<<<1, 128>>>(d, gs);}
CUDA优化原则
最大化并行执行
块内通信
If threads of same block need to communicate, use shared memory and synthreads()
块间通信
If threads of different blocks need to communicate, global memory and split computation into multiple kernels
- No synthronization mechanism between blocks
CPU/GPU parallelism
异步启动:Take advantage of asynchronous(异步) kernel launches by overlapping CPU computations with kernel execution
异步传输:Coming soon: Asynchronous CPU
GPU memory transfer that overlaps with kernel execution
内存优化
尽可能使用更多计算,减少访问,以保证新一代的GPU发布时,程序移植性
极小化CPU
cudaMallocHost()这个函数申请会使内存锁定,速度提高一倍
更多的代码应放在GPU上,以保证数据不会来回导
极大化使用共享内存
共享内存比全局内存速度快两个数量级
优化GPU指令
使用高通量的指令
使用内置函数,规避昂贵指令